复习day11
JAVA多线程如何来实现
方式一:继承Thread类的方式
1、创建一个继承于Thread类的子类
2、重写Thread类中的run():将此线程要执行的操作声明在run()
3、创建Thread的子类的对象
4、调用此对象的start():①启动线程 ②调用当前线程的run()方法
方式二:实现Runnable接口的方式
1、创建一个实现Runnable接口的类
2、实现Runnable接口中的抽象方法:run():将创建的线程要执行的操作声明在此方法中
3、创建Runnable接口实现类的对象
4、将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象
5、调用Thread类中的start():① 启动线程 ② 调用线程的run() —>调用Runnable接口实现类的run()
以下两种方式是jdk1.5新增的!方式三:实现Callable接口
说明:
1、与使用Runnable相比, Callable功能更强大些
2、实现的call()方法相比run()方法,可以返回值
3、方法可以抛出异常
4、支持泛型的返回值
5、需要借助FutureTask类,比如获取返回结果
Future接口可以对具体Runnable、Callable任务的执行结果进行取消、查询是否完成、获取结果等。FutureTask是Futrue接口的唯一的实现类FutureTask 同时实现了Runnable, Future接口。它既可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值
方式四:使用线程池
说明:
提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。类似生活中的公共交通工具。
好处:
1、提高响应速度(减少了创建新线程的时间)
2、降低资源消耗(重复利用线程池中线程,不需要每次都创建)
3、便于线程管理
如何保证线程同步
7种方式
同步方法(即有synchronized关键字修饰的方法. 由于java的每个对象都有一个内置锁,当用此关键字修饰方法时,内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态)
同步代码块(即有synchronized关键字修饰的语句块,该关键字修饰的语句块会自动被加上内置锁,从而实现同步)
使用特殊域变量(volatile)实现线程同步
a.volatile关键字为域变量的访问提供了一种免锁机制
b.使用volatile修饰域相当于告诉虚拟机该域可能会被其他线程更新
c.因此每次使用该域就要重新计算,而不是使用寄存器中的值
d.volatile不会提供任何原子操作,它也不能用来修饰final类型的变量
使用重入锁实现线程同步(ReentrantLock类是可重入、互斥、实现了Lock接口的锁,ReenreantLock类的常用方法有: ReentrantLock() : 创建一个ReentrantLock实例; lock() : 获得锁;unlock() : 释放锁)
使用局部变量实现线程同步(如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响)
使用阻塞队列实现线程同步
使用原子变量实现线程同步(需要使用线程同步的根本原因在于对普通变量的操作不是原子的。
那么什么是原子操作呢?
原子操作就是指将读取变量值、修改变量值、保存变量值看成一个整体来操作
即-这几种行为要么同时完成,要么都不完成)
简述栈和队列的概念
栈是一种后进先出的数据结构,也就是说最新添加的项最早被移出;它是一种运算受限的线性表,只能在栈顶进行插入和删除操作。向一个栈插入新元素叫入栈(进栈),就是把新元素放入到栈顶的上面,成为新的栈顶;从一个栈删除元素叫出栈,就是把栈顶的元素删除掉,相邻的成为新栈顶。
队列是一种先进先出的数据结构。 队列在列表的末端增加项,在首端移除项。它允许在表的首端(队列头)进行删除操作,在表的末端(队列尾)进行插入操作;
- 栈可以用于字符匹配,数据反转等场景
- 队列可以用于任务队列,共享打印机等场景
使用JAVA语句写出一个冒泡排序
public static void main(String[] args) {
int[] arr = {2, 1, 5, 8, 2, 1, 4, 6, 3};
System.out.println("冒泡排序:" + Arrays.toString(bubble(arr)));
}
//冒泡排序
public static int[] bubble(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
arr[j] = arr[j] ^ arr[j + 1];
arr[j + 1] = arr[j] ^ arr[j + 1];
arr[j] = arr[j] ^ arr[j + 1];
}
}
}
return arr;
}
Map、Set、List的区别.写出常见的几个实现类,如果对一个set的数据进行排序,应该如何做?
List和Set继承了Collection接口, List是一个有序可重复的容器, 可以设置多个null, 主要对List接口实现的有ArrayList, LinkedList, Vector. Set是一个无序且不可重复的容器, 可以多个null键, 但始终只有一个null键, 并且会对第一个null键对应的值进行覆盖, 主要对Set接口实现的类有, HashSet, TreeSet. Map就是一个接口, Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的.可以多个null键, 但会对第一个null键的值进行覆盖操作.主要对Map接口实现的类有:HashMap, TreeMap, HashTable
把HashSet保存在ArrayList里,再用Collections.sort()方法比较
把这个HashSet做为构造参数放到TreeSet中就可以排序了
TreeSet底层数据结构采用红黑树来实现,元素唯一且已经排好序;二叉树结构保证了元素的有序性。根据构造方法不同,分为自然排序(无参构造)和比较器排序(有参构造),自然排序要求元素必须实现Compareable接口,并重写里面的compareTo()方法,元素通过比较返回的int值来判断排序序列,返回0说明两个对象相同,不需要存储;比较器排需要在TreeSet初始化是时候传入一个实现Comparator接口的比较器对象,或者采用匿名内部类的方式new一个Comparator对象,重写里面的compare()方法;
简述基础类和包装类的差异,还有几条语句判断true or false,并简述判断依据
包装类型可以为 null,而基本类型不可以
包装类型可用于泛型,而基本类型不可以
基本类型比包装类型更高效
存储方式及位置不同,基本类型是直接将变量存储在栈中,而包装类型是将对象放在堆里面,然后通过引用来使用;
1、包装类Integer跟基本类型int的比较 直接取出包装类事例所包装的数值进行比较。 Integer it1 = 2; Integer it3 = new Integer(2); int i1 = 2; System.out.println(it1 == i1);//true System.out.println(it3 == i1)//true 如果是两个包装类进行比较会有以下几种情况 (1)包装类的实例实际上是引用类型,所以比较的是对象地址,两个不同的对象比较,为false Integer i = new Integer(100); Integer j = new Integer(100); System.out.print(i == j); //false Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false ---------------------------------- [-128,127]之间,那么直接返回内部的缓冲数组中的数据, Integer i = 100; Integer j = 100; System.out.print(i == j); //true
画出SSM框架响应一个浏览器请求的完整流程
1、用户发送请求url至前端控制器DispatcherServlet。
2、DispatcherServlet收到请求调用处理器映射器HandlerMapping。
3、处理器映射器根据请求url找到具体的处理器,生成处理器执行链HandlerExecutionChain(包括处理器对象和处理器拦截器)一并返回给DispatcherServlet。
4、DispatcherServlet根据处理器Handler获取处理器适配器HandlerAdapter,执行HandlerAdapter处理一系列的操作,如:参数封装,数据格式转换,数据验证等操作。
5、执行处理器Handler(Controller,也叫页面控制器)。
6、Handler执行完成返回ModelAndView。
7、HandlerAdapter将Handler执行结果ModelAndView返回到DispatcherServlet。
8、DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、View Reslover解析后返回具体View。
10、DispatcherServlet对View进行渲染视图(即将模型数据model填充至视图中)。
11、DispatcherServlet响应用户。
注意:5中,Controller层 调Service层(其中,Service层调用DAO层),业务层(Service层)主要涉及业务处理,数据访问层(DAO层)主要负责数据持久化的工作,用来连接数据库,完成数据的增删改查操作。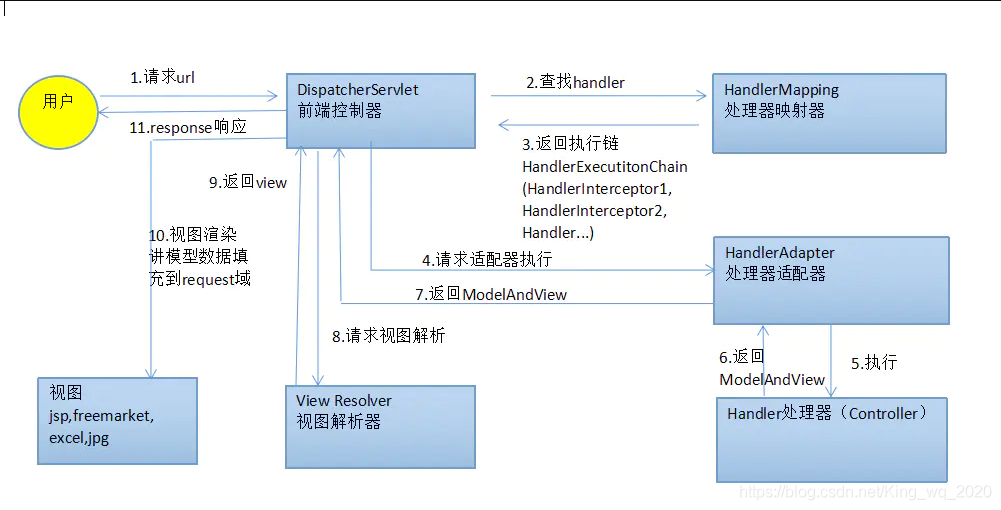
简述一个单例模式和工厂模式,以及常见应用场景
单例:在我们日常的工作中经常需要在应用程序中保持一个唯一的实例,如:Spring的Bean标签,数据库连接池等,由于这些对象都要占用重要的系统资源,所以我们必须限制这些实例的创建或始终使用一个公用的实例,这就是单例模式(Singleton)。
public class Singleton {
private static Singleton instance;
private Singleton (){
}
public static Singleton getInstance(){ //对获取实例的方法进行同步
if (instance == null){
synchronized(Singleton.class){
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
在简单工厂模式中,我们会定义一个创建对象的类,多使用反射的方法来创建具体产品实例,这个类用来封装实例化对象的行为
在软件开发中,当我们需要大量的创某种,某类或者某一批对象的时候,就可以考虑使用简单工厂模式
简单工厂一般分为:普通简单工厂,多方法简单工厂,静态方法简单工
工厂模式:是有一组类似的对象需要创建,包括工厂方法模式,抽象工厂模式
简单工厂模式是由一个工厂对象决定创建出哪一种产品类的实例,在简单工厂模式中,我们会定义一个创建对象的类,多使用反射的方法来创建具体产品实例,这个类用来封装实例化对象的行为,在软件开发中,当我们需要大量的创某种,某类或者某一批对象的时候,就可以考虑使用简单工厂模式(比如查询数据库)
写出hibernate或者mybatis中,一对一与一对多的配置方法
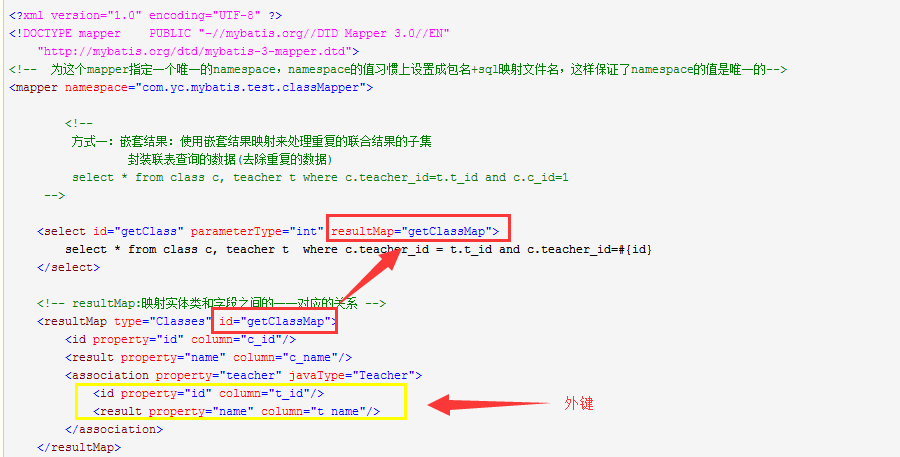
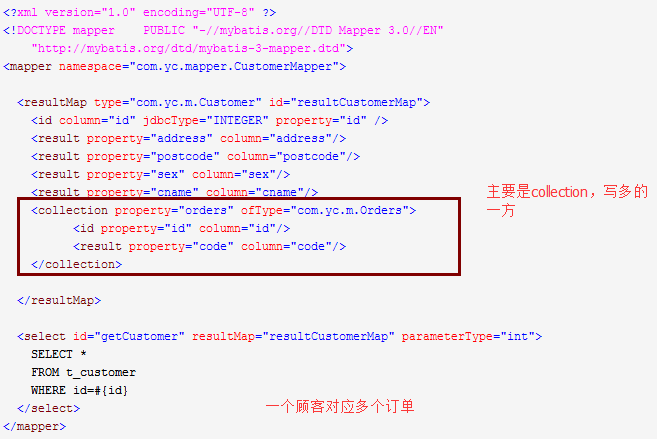
Sql语句中leftjoin和innerjoin有何区别
left join 左连接,假设有两张表,分别是A表和B表,以A表为基准表,如果A表的记录在B表不存在,也能够查询出来.
inner join 内连接,只返回两个表中连接字段相等的行
给一些数据类型,写出对应的xml表达方式和json表达方式
xml
<book id="bk101">
<author>Gambardella, Matthew</author>
<title>XML Developer's Guide</title>
<genre>Computer</genre>
<price>44.95</price>
<publish_date>2000-10-01</publish_date>
<description>An in-depth look at creating applications
with XML.</description>
</book>
json
{
"books": [
{
"id": "bk102",
"author": "Crockford, Douglas",
"title": "JavaScript: The Good Parts",
"genre": "Computer",
"price": 29.99,
"publish_date": "2008-05-01",
"description": "Unearthing the Excellence in JavaScript"
}
]
}
你所做的项目的意义和想法、项目所面向的对象是谁、你负责项目什么模块,项目技术简述、项目后端所选框架和搭建基本流程、项目前端所选框架、项目框架选择的原因、项目所涉及的难题和解决方案、数据库是怎么设计的、你对自己近段时间内的未来规划
近年来,中国的电子商务快速发展,交易额连创新高,电子商务在各领域的应用不断拓展和深化、相关服务业蓬勃发展、支撑体系不断健全完善、创新的动力和能力不断增强。电子商务正在与实体经济深度融合,进入规模性发展阶段,对经济社会生活的影响不断增大,正成为我国经济发展的新引擎。了解电商的开发流程必不可少。
小米商城主要为了方便米粉的购物需求。项目涵盖了javaweb的所有相关知识体系,从前端页面到后台数据库的设计,再到业务逻辑的实现,环环相扣,基本解决了各位米粉对小米产品实现线上购买的需求
销售规模不受网站限制。传统商店只能存储许多商品,而小商店的规模通常会限制企业的规模。在Internet上,即使您在地面上只有一家小商店或根本没有一家商店,开设商店的业务也可能会增长。
不限于存储空间。即使是街头小商店也可以拥有与百货商店一样大的在线商店,只要投资者满意,他们就可以在互联网上投放数千种产品。如今,该国最大的专业拍卖网站同时拥有超过100,000件物品,超过了一些大型超市。
不受地理位置影响。无论您距离商店有多远,您都可以轻松地在国内和国际上在线查找和购买产品。这使消费者群体可以突破地域限制并无限期扩张。
24小时营业时间。该在线商店延长了营业时间,并且一年365天,每天24小时无专人负责的情况下营业,并且照常营业。传统商店通常会开放8到12个小时,在恶劣的天气下,老板和店员需要快速休息一下



