复习day4
一. ArrayList
特点
- 有序可重复
- 底层数据结构是一个“动态增长” 的数组
- 查询效率高,增删效率低
- 如果不指定初始化容量,ArrayList默认初始容量为10,之后添加的元素超过容量默认会以1.5倍扩容。
- 线程不安全
优点:因为数组是一个有序的序列,所以它可以通过下标直接取值——查询效率高
缺点:增删效率低
ArrayList扩容机制
arraylist的底层是用数组来实现的。我们初始化一个arraylist集合还没有添加元素时,其实它是个空数组,只有当我们添加第一个元素时,内部会调用ensureCapacityInternal方法并返回最小容量10,也就是说arraylist初始化容量为10。
当添加的最小容量大于当前数组的长度时,便开始可以扩容了,arraylist扩容的真正计算是在一个grow()里面,新数组大小是旧数组的1.5倍,如果扩容后的新数组大小还是小于最小容量,那新数组的大小就是最小容量的大小,后面会调用一个Arrays.copyof方法,产生一个新的数组。
二. ArrayList和Vector区别
- Vector是线程安全的,ArrayList不是线程安全的。
- ArrayList扩容机制1.5倍,Vector扩容机制2倍
三. LinkedList
- 有序的序列
- 底层的数据结构双向链表,jdk6以及之前是双向循环链表
- 链表结构的特点:查询效率很低,每次都会从头节点开始遍历
- 增删效率高,只会涉及到相邻节点的移动
栈列 - 先进后出
队列 - 先进先出
add方法
调用add()方法添加元素,会调用linklast(),把新添加的元素放在原链表最后一位
首先获取原链表最后一个元素,根据当前输入的元素构建一个node,把原最后一位元素作为新构建的元素中pre对应的变量
判断添加前的最后一位是否为空,如果为空,说明第一次进入,链表之前没有任何元素新添加的一个node也是first变量对应的元素
如果添加前的最后一位不为空,则未添加前的最后一位元素的next变量被新添加的元素覆盖
链表长度加1,链表修改统计加1
get方法
- 首先,校验输入的下标是否满足linkedlist中的长度范围,如果不满足,抛出异常
- 如果满足,调用node()方法,首先把原长度除以2,判断当前输入的下标是在上半部分还是下半部分
- 如果在上半部分,从上往下遍历,如果在下半部分,从后往前遍历.
- 最后一个元素就是要找的元素
remove方法
LinkedList.remove()
无参方法会直接删除链表的头结点first
LinkedList.remove(Object o)删除传入的对象
如果传入对象为null遍历链表 , 当有节点的值为null时调用unlink方法删除节点
如果传入对象不为null同样遍历全表 , 调用对象的equals方法判断有没有与传入对象相等的节点 , 如果有调用unlink方法删除节点
其他情况返回false
LinkedList.remove(int index)删除第index个链表节点
先调用checkElementIndex(index)方法判断传入第index个节点是否存在
如果存在调用unlink(node ())方法删除元素
unlink()方法解析
创建三个临时变量存储传入节点的信息
element 存储节点的对应对象
node
next 存储下一个节点的地址 node
prev 存储上一个节点的地址 如果上一个节点为null(prev=null)说明传入节点为头结点,此时将下一个节点的地址赋值给first
其他则将上一个节点的next指向传入节点的下一个节点,传入节点的prev赋值为null
如果传入节点之后没有节点(next=null)说明传入节点为尾节点,此时上一个节点赋值给尾节点
其他则将上一个节点的地址赋值给下一个节点的prev,将传入节点的next赋值为null
最后将传入节点的值赋值为null
链表中的节点个数-1,操作数+1
返回删除节点存储的对象
四. ArrayList和LinkedList区别
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
ArrayList查询效率高,LinkedList增删效率高
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
五. List和Set区别
两个接口都是继承自Collection,是常用来存放数据项的集合,主要区别如下:
- List和Set之间很重要的一个区别是是否允许重复元素的存在,在List中允许插入重复的元素,而在Set中不允许重复元素存在。
- 与元素先后存放顺序有关,List是有序集合,会保留元素插入时的顺序,Set是无序集合。
- List可以通过下标来访问,而Set不能。
六.HashSet
特点
- HashSet实现了set接口,底层是HashMap
- 存储的是对象,数据是无序不可重复的
add方法——添加数据
- 把对象添加到容器之前,会根据对象调用hashCode方法,得到一个哈希值
- 通过这个哈希值直接定位元素的物理位置,如果没有被占用,直接存储,如果有数据,就产生了哈希碰撞或者哈希冲突
- 但这个时候还不能确定是同一个对象,继续调用对象的equals方法,如果返回true,说明是同一个对象,则拒绝添加
底层数据结构
- 散列表
- 桶数组 + 链表 + 红黑树
七.HashMap
特点
- 针对key无序不可重复
- 数据存储的形式为key-value
- 线程不安全
- 底层数据结构
- JDK8之前——桶数组+链表
- JDK8之后——桶数组+链表+红黑树
HashMap为什么线程不安全?
- 多线程下扩容死循环
- 多线程的put可能导致元素的丢失。
- put和get并发时,可能导致get为null
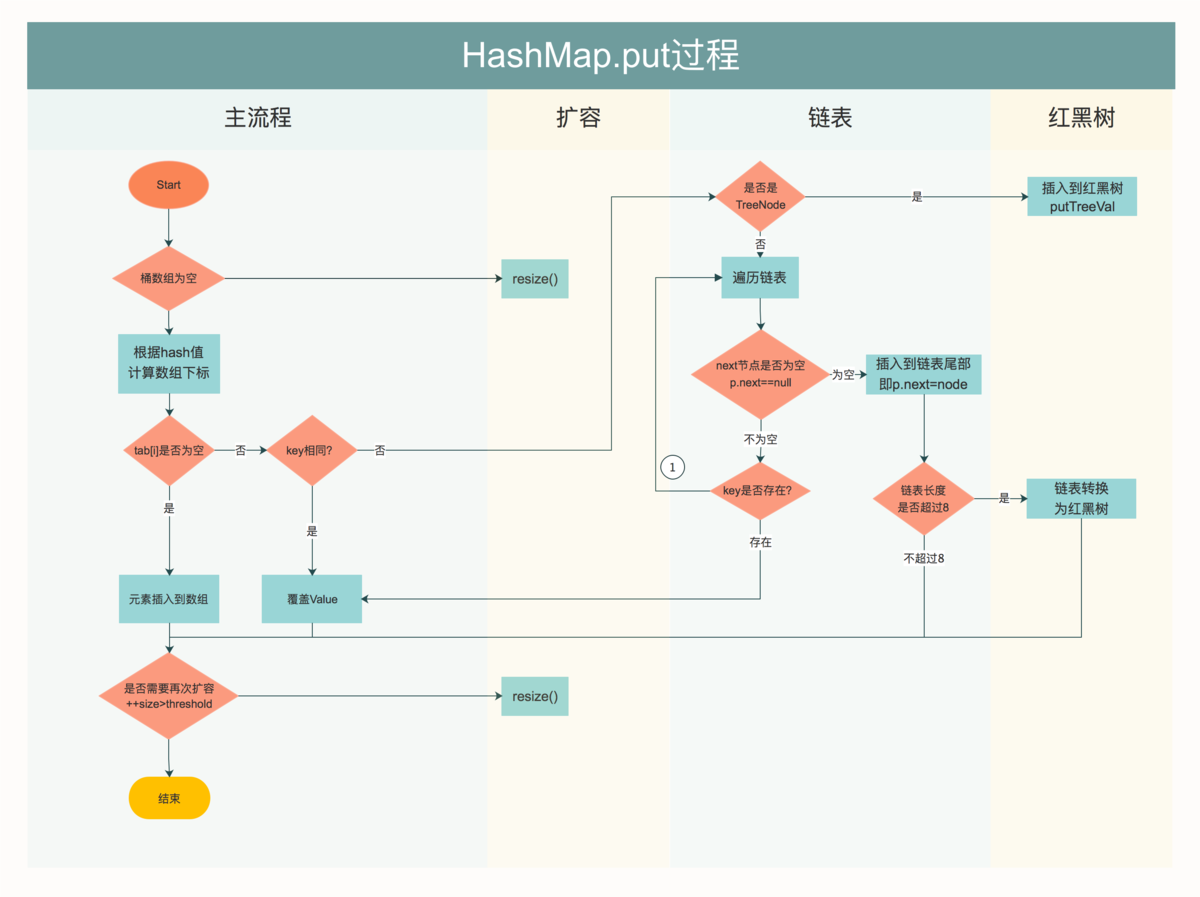
put方法
- 首先根据 key 的值计算 hash 值,找到该元素在数组中存储的下标;
- 如果数组是空的,则调用 resize 进行初始化;
- 如果没有哈希冲突直接放在对应的数组下标里;
- 如果冲突了,且 key 已经存在,就覆盖掉 value;
- 如果冲突后,发现该节点是红黑树,就将这个节点挂在树上;
- 如果冲突后是链表,判断该链表是否大于 8 ,如果大于 8 并且数组容量小于 64,就进行扩容;如果链表节点大于 8 并且数组的容量大于 64,则将这个结构转换为红黑树;否则,链表插入键值对,若 key 存在,就覆盖掉 value。
以上条件判断完, 数据放入到数组或者链表或者红黑树里面,计数器+1,然后判断+1的长度, 是否达到了负载因子(0.75)的阈值, 怎么计算阈值(比如: 初始化桶数组16个长度 * 0.75 = 12, 当+1的值大于12时, 就要告诉桶数组要扩容了), 扩容多少(他是按2^n次方扩容的, 初始化长度16, 扩一次乘以2 = 32, 所以这次扩容之后的长度为32).
红黑树拓展:
一开始红黑树是由二叉查找树(二叉平衡树)延伸过来的, 什么是二叉查找树, 左子树节点的的值小于或等于根节点的值, 右子树节点的值大于或等于根节点的值, 所以每次查找某个数据的时候, 二分查找的算法, 从根节点开始找, 查找的数据大于根节点的往右子树找, 小于的往左子树找, 查找的最大次数为树的高度, 但是会有个问题, 当插入的数据导致树的节点大部分为右节点或者左节点的时候, 会导致查找的效率变低, 时间复杂度变为线性的, 所以为了解决这种情况, 诞生出了自平衡的二叉查找树(红黑树).
规则:
① 每一个节点要么都是红色, 要么都是黑色.
② 根节点为黑色
③ 叶子节点为黑色节点(存放的都是NIL空节点)
④ 每个红色节点有两个黑色子节点
⑤ 从给定节点到其后代子节点的每一条路径的都包含相同数量的黑色节点, 并且没有一条路径会是别的路径长度的两倍.
当有打破以上五个规则的其中一个的时候, 自平衡的红黑树会使用两种方式( 变色或者旋转 ), 从新维护这棵树. 变色的话就是将节点换成黑色或者红色, 会影响到其他节点的变色. 旋转的话, 分为左旋: 逆时针转动, 作为父节点向左移动,变为左孩纸, 右节点变为父节点.
红黑树变成链表为什么是6不是8
上面说到,当链表长度达到阈值8的时候会转为红黑树,但是红黑树退化为链表的阈值却是6,为什么不是小于8就退化呢?比如说7的时候就退化,偏偏要小于或等于6?
主要是一个过渡,避免链表和红黑树之间频繁的转换。如果阈值是7的话,删除一个元素红黑树就必须退化为链表,增加一个元素就必须树化,来回不断的转换结构无疑会降低性能,所以阈值才不设置的那么临界。
两种遍历方式
public static void main(String[] args) {
Map<Integer,String> maps = new HashMap<>();
maps.put(1,"java");
maps.put(2,"python");
maps.put(3,"php");
//获取maps集合中的所有的value
Collection<String> values = maps.values();
System.out.println(values);//[java, php]
//手写map集合的迭代方式
//System.out.println(maps);
//第一种方式 - 将map集合中所有的key全部取出来放入到一个Set集合中.
//set集合 - 无序不可重复,map集合的key也是无序不可重复.
Set<Integer> sets = maps.keySet();
//遍历set集合
Iterator<Integer> iter = sets.iterator();
while(iter.hasNext()){
Integer key = iter.next();
String value = maps.get(key);
System.out.println(key+":"+value);
}
//第二种方式 - 将map集合中的每对key-value封装到了一个内置的Entry对象中
//然后将每个entry对象放入到Set集合中
Set<Map.Entry<Integer,String>> entries = maps.entrySet();
Iterator<Map.Entry<Integer,String>> iter2 = entries.iterator();
while(iter2.hasNext()){
Map.Entry<Integer,String> e = iter2.next();
Integer key = e.getKey();
String value = e.getValue();
System.out.println(key+"->"+value);
}
//jdk8.x提供的map集合迭代的方式
System.out.println("====");
maps.forEach((k,v)-> System.out.println(k+"="+v));
}
八.HashMap和HashSet区别
HashSet的底层是HashMap
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
九. HashMap和HashTable区别
HashMap 是 HashTable 的轻量级实现,他们都完成了Map 接口,主要区别在于 HashMap 允许 null key 和 null value,由于非线程安全,效率上可能高于 Hashtable。主要区别如下:
- HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
- HashMap 把 Hashtable 的 contains 方法去掉了,改成 containsValue 和 containsKey。因为 contains 方法容易让人引起误解。
- HashMap的默认初始扩容大小为16,之后每次扩容容量为原来的2倍。HashTable的默认初始大小为11,之后每次扩容容量变为原来的2n+1
- JDK8.x以后HashMap在解决哈希冲突时有了较大变化,当链表大于阈值(默认为8)时将链表转换为红黑树,HashTable没有这样的机制。
- HashTable 的方法是 Synchronize 的,而 HashMap 不是,在多个线程访问 Hashtable 时,不需要自己为它的方法实现同步,而 HashMap 就必须为之提供外同步。
- Hashtable 和 HashMap 采用的 hash/rehash 算法都大概一样,所以性能不会有很大的差异。
十.HashSet和TreeSet区别
一、HashSet
HashSet内部的数据结构是哈希表,是线程不安全的。
HashSet当中,保证集合中元素是唯一的方法。
通过对象的hashCode和equals方法来完成对象唯一性的判断。
假如,对象的hashCode值是一样的,那么就要用equals方法进行比较。
假如,结果是true,那么就要视作相同元素,不存。
假如,结果是false,那么就视为不同元素,存储。
注意了,假如,元素要存储到HashCode当中,那么就一定要覆盖hashCode方法以及equals方法。
二、TreeSet
TreeSet能够对Set集合当中的元素进行排序,是线程不安全的。
TreeSet当中,判断元素唯一性的方法是依据比较方法的返回结果是否为0,假如是0,那么是相同的元素,不存,假如不是0,那么就是不同的元素,存储。
TreeSet对元素进行排序的方式:
1、元素自身具备比较功能,也就是自然排序,需要实现Comparable接口,并覆盖其compareTo方法。
2、元素自身不具备比较功能,那么就要实现Comparator接口,并覆盖其compare方法。
除此之外,还要注意了,LinkedHashSet是一种有序的Set集合。
也就是其元素的存入和输出的顺序是相同的。
十一. List,Set,Map区别
一句话: List和Set继承了Collection接口, List是一个有序可重复的容器, 可以设置多个null, 主要对List接口实现的有ArrayList, LinkedList, Vector. Set是一个无需且不可重复的容器, 可以多个null键, 但始终只有一个null键, 并且会对第一个null键对应的值进行覆盖, 主要对Set接口实现的类有, HashSet, TreeSet. Map就是一个接口, Map 的 每个 Entry 都持有两个对象,也就是一个键一个值,Map 可能会持有相同的值对象但键对象必须是唯一的.可以多个null键, 但会对第一个null键的值进行覆盖操作.主要对Map接口实现的类有:HashMap, TreeMap, HashTable.
十二. ArrayList和HashSet区别
1.HashSet 是无序不重复!
唯一性保证. 重复对象equals方法返回为true ,重复对象hashCode方法返回相同的整数
HashSet其实就是一个HashMap,只是你只能通过Set接口操作这个HashMap的key部分,
2.ArrayList是可重复的 有序的
特点:查询效率高,增删效率低 轻量级 线程不安全。
arraylist:在数据的插入和删除方面速度不佳,但是在随意提取方面较快
十三. HashMap和TreeMap区别
HashMap的底层是Array,所以HashMap在添加,查找,删除等方法上面速度会非常快。而TreeMap的底层是一个Tree结构,所以速度会比较慢。
另外HashMap因为要保存一个Array,所以会造成空间的浪费,而TreeMap只保存要保持的节点,所以占用的空间比较小。
HashMap如果出现hash冲突的话,效率会变差,不过在java 8进行TreeNode转换之后,效率有很大的提升。
TreeMap在添加和删除节点的时候会进行重排序,会对性能有所影响。
十四. 比较器接口[java.util.Comparator] 可比较接口[java.lang.Comparable]
Comparable是排序接口,若一个类实现了Comparable接口,就意味着“该类支持排序”。而Comparator是比较器,我们若需要控制某个类的次序,可以建立一个“该类的比较器”来进行排序。
Comparable相当于“内部比较器”,而Comparator相当于“外部比较器”。
两种方法各有优劣, 用Comparable 简单, 只要实现Comparable 接口的对象直接就成为一个可以比较的对象,但是需要修改源代码。 用Comparator 的好处是不需要修改源代码, 而是另外实现一个比较器, 当某个自定义的对象需要作比较的时候,把比较器和对象一起传递过去就可以比大小了, 并且在Comparator 里面用户可以自己实现复杂的可以通用的逻辑,使其可以匹配一些比较简单的对象,那样就可以节省很多重复劳动了。
十五.TreeSet[C]
简单了解一下
Set[I] - SortedSet[I] - TreeSet[C] - 底层是TreeMap[C] - 使map集合的key根据定制的规则来进行排序.
Set - 无序不可重复的.
TreeSet - 不可重复的,但是可以根据定制的排序规则来进行排序.
十六.数组排重
//根据下标进行删除
public static int[] delByIndex(int[] arr,int index){
//校验
if(null == arr || arr.length==0 || index<0 || index>arr.length-1)
return arr;
//1. 定义新的数组
int[] temp = new int[arr.length-1]; //因为根据指定下标删除 删除的个数为1
//2. 定义下标计数器
int pos = 0;
for (int i = 0; i < arr.length; i++) { //遍历arr
if (i != index){
temp[pos++] = arr[i];
}
}
return temp;
}
/**
* 调用delByIndex
* {1,2,3,4}
*
* 遍历到arr i从0开始 arr[i]
* 和i后面的所有的值进行比较arr[j]
* 如果arr[i] == arr[j] - delByIndex(arr,j);
*/
public static int[] delDoubleElement2(int[] arr){
if(null == arr || arr.length==0)
return arr;
for (int i = 0; i < arr.length; i++) {
for (int j = i+1; j <arr.length ; j++) {
if (arr[i] == arr[j]){
//删除j下标对应的数据
// arr = {1,1,2,3,3,1,4,2,1};
arr = delByIndex(arr,j);
j--; //防止下标左移漏掉
}
}
}
return arr;
}
/**
* 删除指定元素!!!
*
* 数组的长度一旦确定了,就不能改变 - 删除-"假的"
* * @param arr 原数组
* * @param target 需要删除的元素
* * @return 新的数组,一定不包含target值
*/
public static int[] delByTarget(int[] arr,int target){
//确定一个新的数组的关键, - 数组的元素类型 / 数组的长度
int count = 0; //计数器
for (int i = 0; i < arr.length; i++) { //确定target的个数
if (arr[i] == target){
count++;
}
}
if (count == 0){ //判断一下target是否存在
return new int[-1]; //无所谓返回什么 直接抛出错误信息即可
}
int[] arr1 = new int[arr.length-count]; //新数组
int index = 0;
for (int i = 0; i < arr.length; i++) { //遍历原来的数组
if (arr[i] != target){
arr1[index] = arr[i];
index ++;
}
}
return arr1;
}
/**
* 去重!
* 引用和对象
*
* arr -> [1,2,1,2,3,3,4,2]
*
* temp -> [0,0,0,0,0,0,0,0]
*
* 永远将arr[0]依次放入到temp[pos++] = arr[0]
* temp -> [1,2,3,4,0,0,0,0]
*
* 立即到arr中将所有的arr[0]这个数值全部删除
* int[] trr = delByTarget(arr,arr[0]);//
* arr = trr;
* //arr -> []
*
* //arr的长度为0
*
* 核心的原则:不断改变arr的地址
*
* arr = []
* @param arr
* @return
*/
public static int[] delDoubleElement(int[] arr){
//判断数组的有效性
//java.lang.NullPointerException 空指针异常 - null.东西[/属性/方法 - 成员]
if(null == arr || arr.length==0)
return arr;
//定义一个新的数组,长度和原来的数组一样
int[] temp = new int[arr.length];
//定义一个下标计数器
int pos=0;
do{
//永远将arr[0]依次放入到temp[pos++] = arr[0]
temp[pos++] = arr[0];
// 立即到arr中将所有的arr[0]这个数值全部删除
arr = delByTarget(arr,arr[0]); // 核心,包含的知识点,本质
//循环退出
if(arr.length==0)
break;
}while(true);
temp = Arrays.copyOf(temp,pos);
return temp;
}
十六.Collection和Collections区别
Collection是一个接口
Collections是一个工具类



