Hadoop介绍
Apache Hadoop是一个应用java语言实现的软件框架,再由大量的廉价的计算机组成的集群中运行海量数据的分布式并行计算框架,它可以让应用程序支持上千个节点和PB级别的数据。Hadoop是项目的总称,主要是由分布式存储(HDFS)、和分布式并行计算(MapReduce)等组成。
Google的关键技术与思想
GFS HDFS
Map-Reduce MapReduce
Bigtable Hbase
Hadoop源起——Lucene
Doug Cutting开创的开源软件,用java书写代码,实现与 Google类似的全文搜索功能,它提供了全文检索引擎的架构, 包括完整的查询引擎和索引引擎
早期发布在个人网站和SourceForge,2001年年底成为apache 软件基金会jakarta的一个子项目
Lucene的目的是为软件开发人员提供一个简单易用的工具包, 以方便的在目标系统中实现全文检索的功能,或者是以此为基 础建立起完整的全文检索引擎
对于大数据量的场景,Lucene面对与Google同样的困难。
迫使 Doug Cutting学习和模仿Google解决这些问题的办法 一个微缩版:Nutch
从lucene到nutch,从nutch到hadoop
2003-2004年,Google公开了部分GFS和Mapreduce思想的细 节,以此为基础Doug Cutting等人用了2年业余时间实现了DFS 和Mapreduce机制,使Nutch性能飙升
Yahoo招安Doug Cutting及其项目
Hadoop 于 2005 年秋天作为 Lucene的子项目 Nutch的 一部分 正式引入Apache基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
名字来源于Doug Cutting儿子的玩具大象
什么是hadoop
什么是Hadoop?
- Hadoop是一个开源的、可靠的、可扩展的分布式并行计算框架
- 主要组成:分布式文件系统HDFS和MapReduce计算模型
- 作者:Doug Cutting
- 语言:Java,支持多种编程语言,如Python、C++
**Hadoop项目主要包括以下四个模块 **
- Hadoop Common: 为其他Hadoop模块提供基础设施。
- Hadoop HDFS: 一个高可靠、高吞吐量的分布式文件系统
- Hadoop MapReduce: 一个分布式的离线并行计算框架
- Hadoop YARN: 一个新的MapReduce框架,任务调度与资源管理
HDFS架构图
HDFS - Hadoop Distributed Filesystem - Hadoop分布式的文件系统
数据冗余存储
最为常见的就是分布式存储中,多个节点存储同一份数据,增强可用性与可靠性
写文件:
数据冗余方式写入,将一个文件存储到多个节点中,并且在不同的机架上
文件-》默认一个文件存3份(按块存储,每块3份) 1g=》3g
存储是按照块来存储的,hadoop2.x数据块默认大小是128M
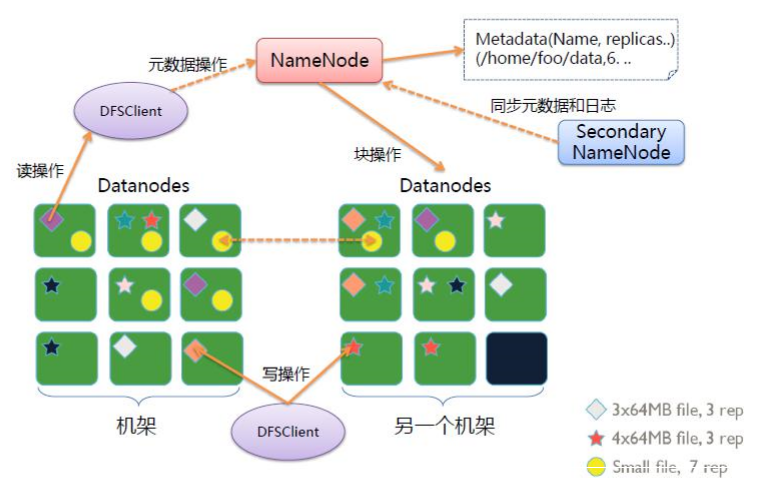
NameNode
NameNode是整个文件系统的管理节点。它维护着
- 整个文件系统的文件目录树
- 文件/目录的元信息和每个文件对应的数据块列表(元信息:文件名,副本数,存储节点)
- 接收用户的操作请求
DataNode
- 提供真实文件数据的存储服务
- 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。
- HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block. 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
- Replication。多副本。默认是三个
Hadoop的安装方式
- 单机模式 - 没有任何的守护进程
- 单机伪分布模式 - Hadoop也可以以伪分布式模式在单节点上运行,其中每个Hadoop守护程序都在单独的Java进程中运行。
- 集群分布模式/完全分布式 - 不同节点运行不同的机器上
- 高可用架构



