环境准备
CentOS7
JDK8.x
hadoop-2.7.6.tar.gz
tar zvxf hadoop-2.7.6.tar.gz
上传至/opt/soft目录中[修改soft 777权限]
sudo chmod -R 777 /opt/soft
JDK配置
先卸载默认的openjdk
查看openjdk的位置
-- 查看所有软件包是否安装 [success@localhost ~]$ rpm -qa | grep java java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64 javapackages-tools-3.4.1-11.el7.noarch tzdata-java-2017b-1.el7.noarch java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64 java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64 java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64 python-javapackages-3.4.1-11.el7.noarch卸载 - root账户
除了.noarch不需要卸载,其余全部卸载
[root@localhost success]# rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.131-11.b12.el7.x86_64 [root@localhost success]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.141-2.6.10.5.el7.x86_64 [root@localhost success]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.141-2.6.10.5.el7.x86_64 [root@localhost success]# rpm -e --nodeps java-1.8.0-openjdk-1.8.0.131-11.b12.el7.x86_64 [root@localhost success]# rpm -qa | grep java javapackages-tools-3.4.1-11.el7.noarch tzdata-java-2017b-1.el7.noarch python-javapackages-3.4.1-11.el7.noarch
在/opt/目录下新建soft目录,并且修改权限为777
[success@localhost opt]$ mkdir soft [success@localhost opt]$ sudo chmod 777 soft利用xftp工具将jdk压缩包进行上传 - 解压
在/etc/profile文件中的末尾添加内容如下:
-rw-r--r--. 1 root root 1795 11月 6 2016 profile授权
[success@localhost etc]$ sudo chmod 777 profile进行编辑,添加内容如下:
export JAVA_HOME=/opt/soft/jdk1.8.0_172 export PATH=$PATH:${JAVA_HOME}/bin比如以后要配置mysql
export JAVA_HOME=/opt/soft/jdk1.8.0_172 export PATH=$PATH:${JAVA_HOME}/bin export PATH=$PATH:/opt/soft/mycat/bin
重新将/etc/profile文件设置成原来的权限[忽略]
~~~cmd
[success@localhost etc]$ java -version
bash: java: 未找到命令...
说明/etc/profile文件的设置并没有生效
[success@localhost etc]$ source profile
[success@localhost etc]$ java -version
bash: /opt/soft/jdk1.8.0_172/bin/java: 权限不够
jdk目录下的bin下的命令没有x权限[可执行权限]
-rw-rw-r--. 1 success success 7734 10月 14 16:19 java
[success@localhost bin]$ pwd
/opt/soft/jdk1.8.0_172/bin
[success@localhost bin]$ sudo chmod +x java
[sudo] success 的密码:
对不起,请重试。
[sudo] success 的密码:
[success@localhost bin]$ java -version
java version "1.8.0_172"
Java(TM) SE Runtime Environment (build 1.8.0_172-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
[success@localhost bin]$ sudo chmod +x javac
测试
[success@localhost bin]$ java -version java version "1.8.0_172" Java(TM) SE Runtime Environment (build 1.8.0_172-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.172-b11, mixed mode)
解压hadoop
解压到当前目录
[success@localhost soft]$ tar -zxvf hadoop-2.7.6.tar.gz将hadoop-2.7.6/share/doc目录删除,节省磁盘空间.[可选操作]
修改如下三个文件
hadoop2.7.6/etc/hadoop目录
[success@localhost hadoop]$ vi hadoop-env.sh # 第25行 [success@localhost hadoop]$ vi mapred-env.sh # 第16行 [success@localhost hadoop]$ vi yarn-env.sh # 在24行处添加 [success@localhost hadoop]$在每个文件中添加:
export JAVA_HOME=/opt/soft/jdk1.8.0_172hadoop中的四个核心模块对应四个默认配置文件
四个核心文件配置
虚拟机主机名和虚拟机的ip地址之间进行映射
vi /etc/hosts
添加内容如下:
192.168.2.30 localhost.success
core-site.xml
官方的参考的地址:
https://hadoop.apache.org/docs/r2.7.6/hadoop-project-dist/hadoop-common/core-default.xml
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://localhost.success:9000</value> </property> <!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/data/tmp</value> </property>hdfs-site.xml
<!-- 设置dfs副本数,不设置默认是3个 --> <property> <name>dfs.replication</name> <value>1</value> </property>笔试题:一个文件160M,副本数2,块大小128m,实际存储空间多少?块数量多少?
块数量-160/128->1 …. 32M -> 需要2个块 * 副本数2 = 4个块
实际存储空间->160*4=640
修改slave文件 - 指定从节点的位置
主节点是namenode,从节点是datanode
localhost格式化文件系统 - 仅仅需要一次
如果哪天hdfs崩溃了,必须先干掉**/opt/soft/hadoop-2.7.6/data/tmp**,再重新格式化,还需要干掉/opt/soft/hadoop-2.7.6/logs
success@localhost hadoop-2.7.6]$ bin/hdfs namenode -format出现如下info信息,表示成功
/************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost.success/192.168.2.22 ************************************************************/之后可以观察之前创建的data/tmp目录中新增的变化
Start NameNode daemon and DataNode daemon
[success@localhost hadoop-2.7.6]$ sbin/hadoop-daemon.sh start namenode starting namenode, logging to /opt/soft/hadoop-2.7.6/logs/hadoop-success-namenode-localhost.success.out [success@localhost hadoop-2.7.6]$ sbin/hadoop-daemon.sh start datanode starting datanode, logging to /opt/soft/hadoop-2.7.6/logs/hadoop-success-datanode-localhost.success.out查看HDFS外部UI界面
windows中,通过ip:端口
http://192.168.2.22:50070linux中,还可以通过主机名:端口号
http://localhost.success:50070查看当前的进程
如果遇到如下错误:
[success@localhost hadoop-2.7.6]$ jps -bash: /opt/soft/jdk1.8.0_172/bin/jps: 权限不够[success@localhost jdk1.8.0_172]$ cd bin [success@localhost bin]$ ls appletviewer javac javaws jinfo jsadebugd orbd serialver ControlPanel javadoc jcmd jjs jstack pack200 servertool extcheck javafxpackager jconsole jmap jstat policytool tnameserv idlj javah jcontrol jmc jstatd rmic unpack200 jar javap jdb jmc.ini jvisualvm rmid wsgen jarsigner javapackager jdeps jps keytool rmiregistry wsimport java java-rmi.cgi jhat jrunscript native2ascii schemagen xjc [success@localhost bin]$ sudo chmod +x jps [sudo] success 的密码:
[success@localhost hadoop-2.7.6]$ jps 8289 Jps 3636 NameNode 3690 DataNode打开windows浏览器:http://localhost.success:50070即可
测试HDFS环境
创建目录,HDFS中有用户主目录的概念,和LINUX中一样
当执行这句命令的时候,在hdfs中自动创建用户主目录/user/success
success/input就会自动在/user/success目录中
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -mkdir -p success/input删除hdfs目录
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -rm -r success/input上传文件到HDFS
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -put etc/hadoop/core-site.xml etc/hadoop/hdfs-site.xml /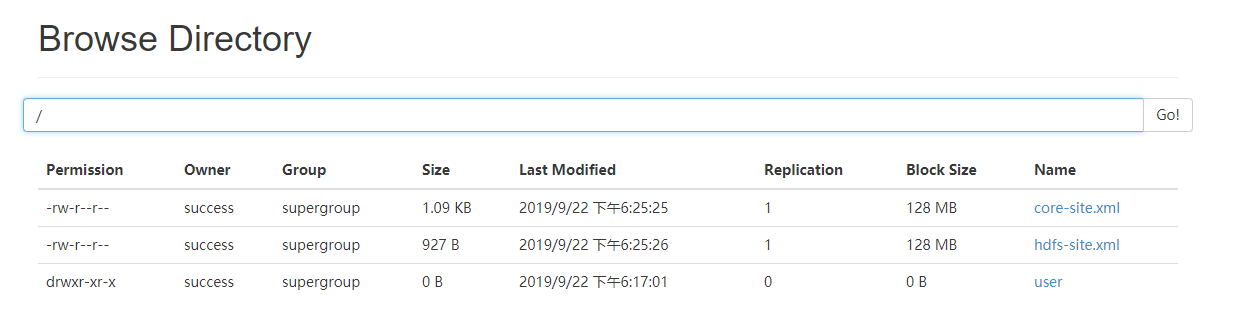
读取hdfs的文件
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -text /core-site.xml下载文件到本地
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -get /core-site.xml /home/success/get-site.xml注意:
- HDFS不支持多用户并发写入
- HDFS不适合存储量小文件
删除文件
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -rm master/input/student.txt
yarn模块设置
Configure parameters as follows:
etc/hadoop/mapred-site.xml:<configuration> <!-- 指定mr运行在yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>etc/hadoop/yarn-site.xml:<!-- reducer获取数据的方式 指定启动运行mapreduce上的nodemanager的运行服务 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 指定resourcemanager主节点机器 --> <property> <name>yarn.resourcemanager.hostname</name> <value>localhost.success</value> </property>Start ResourceManager daemon and NodeManager daemon
[success@localhost hadoop-2.7.6]$ sbin/yarn-daemon.sh start resourcemanager starting resourcemanager, logging to /opt/soft/hadoop-2.7.6/logs/yarn-success-resourcemanager-localhost.success.out [success@localhost hadoop-2.7.6]$ sbin/yarn-daemon.sh start nodemanager starting nodemanager, logging to /opt/soft/hadoop-2.7.6/logs/yarn-success-nodemanager-localhost.success.out [success@localhost hadoop-2.7.6]$ jps 9842 Jps 3636 NameNode 3690 DataNode 9658 ResourceManager 9743 NodeManager启动浏览器
HelloWorld案例
测试环境:运行一个mapreduce,wordcount单词统计案例
mapreduce分成五个节点
input->map()->shuffle->reduce()->output
操作步骤
将mapreduce运行在yarn上,需要打jar包
新建一个数据文件,用于测试mapreduce
将数据文件file_text.txt从本地上传到HDFS
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -put /opt/data/file_text.txt /user/success/success/input使用官方提供的示例jar包
/opt/soft/hadoop-2.7.6/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar
执行
注意hdfs中不能提前存在输出路径/user/success/success/output
[success@localhost hadoop-2.7.6]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount /user/success/success/input /user/success/success/output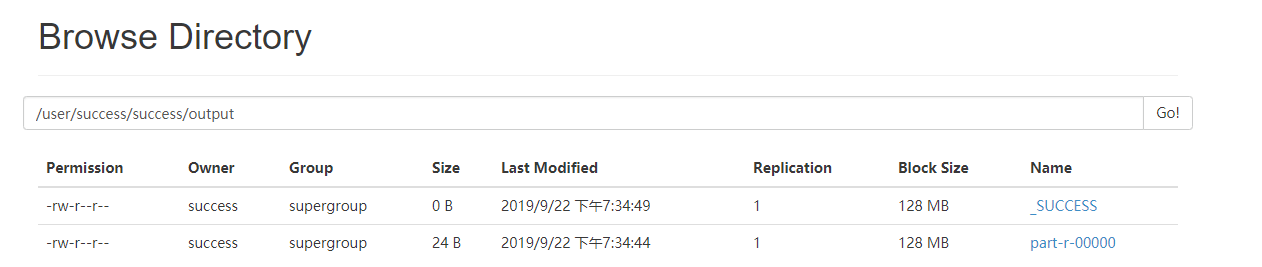

查看输出文件
[success@localhost hadoop-2.7.6]$ bin/hdfs dfs -text /user/success/success/output/p* ABCDA 1 Hello 1 World 1删除输出文件
bin/hdfs dfs -rm -r /user/success/success/out*
分析map和reduce[补充]
文件:
[success@localhost datas]$ cat wordcount.txt python hello java java mysql hello python javaMap-Reduce Framework Map input records=3 Map output records=8 Map output bytes=79 Map output materialized bytes=54 Input split bytes=133 Combine input records=8 Combine output records=4 Reduce input groups=4 Reduce shuffle bytes=54 Reduce input records=4 Reduce output records=4 Spilled Records=8 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=327 CPU time spent (ms)=2960 Physical memory (bytes) snapshot=283295744 Virtual memory (bytes) snapshot=4159811584 Total committed heap usage (bytes)=138981376wordcount单词统计经过的过程阶段
input->map->shuffle->reduce->output
Map input records=3
数据是怎么进入到map(),map是方法
<0,python hello java> <17,java mysql hello> <偏移量,python java>Map output records=8
map阶段做的事情 - 不会涉及到统计,排序.
经过map()函数处理完之后,数据的格式
确定key
shuffle阶段[洗牌] - 由框架自动完成了 - 无需程序员自己写代码的
Reduce input groups=4
负责统计
Reduce output records=4
今天需要掌握的内容
- namenode和datanode的含义
- wordcount整个执行的阶段[mapreduce的一个过程]



