JDBC概述
jdbc - java database connectivity - java数据库连接
使用java编写的程序来访问数据库的技术.优势在于可以使用同一套java代码来访问市面上不同的数据库.
作用:为访问不同的数据库来提供统一的方式.
市面上主流的关系型数据库:sqlserver,oracle,mysql
非关系型数据库:文档型数据库 - mongodb.键值对数据库-redis
属于早期的JAVAEE[jakartaEE]十三种核心技术中的一种.
这个技术已经被淘汰了.属于**持久层[数据访问层 - 和DB交互的层]**的最传统的技术.持久层框架的底层都是采用的jdbc技术.
市面上有很多持久层的框架,主流的ORM[Object Relation Mapping 对象关系映射]框架.
ORM本质上是一个思想,在这个思想下诞生了很多ORM框架[实际上就是ORM思想的实现者]
3-1. 非移动互联网时代 - Hibernate框架[全自动的ORM框架 - 不需要写sql语句 - 不能进行sql优化]
3-2. 大数据时代 - **Mybatis[**半自动的ORM框架,需要写sql,但是相对于jdbc技术稍微简单一点,可以进行sql优化]
3-3. 国产的Mybatis-plus框架 - 又是对Mybatis的进一步的封装
核心的api
Driver[I]
驱动接口 - 驱动实现类是由各个db厂商去实现的.
java.sql.Driver[I]
驱动jar - mysql-connector-java-8.0.25.jar - 本质就是对sun公司制定的Driver接口的实现类.
想要使用哪个db厂商的db,那么就导入哪个db的驱动jar.
-- 历史 -- java-sun公司-oracle公司收购了[oracle数据库-收费] 伪代码 java-oracle //jdbc编程第一步 - 创建一个驱动类对象 OracleDriver driver = new OraclerDiver(); -- java语言发展壮大了,mysql原先是不属于oracle. -- java-mysql MysqlDriver driver = new MysqlDriver(); //代码的可维护性不是太好.java代码不能随便切换数据库了; //因为db厂商不一样[类,接口命名都不一样] //有多少个db,就得写多少套java代码 //sun考虑到这一点,制定了一系列的接口[居多]和类 //接口作用就是用来指定一个规范,"契约". //jdk-api - 查得到java.sql.Driver[I] //sun - db厂商下的db要和java交互的.必须遵守我的规范.你们这些db厂商只要给我实现这个规范接口. public interface Driver{ Driver getInstance(); } //oracle遵守规范 //sqlserver,mysql遵守规范 public class OracleDriver implements Driver{ @Override public Driver getIntance(){ //db是不同的,每个厂商程序根据具体的db产品来的 //具体的实现肯定是由db厂商去实现... return new OracleDriver(); } } //sqlserver - ms public class SqlServerDriver implements Driver{ @Override public Driver getIntance(){ //db是不同的,每个厂商程序根据具体的db产品来的 //具体的实现肯定是由db厂商去实现... return new SqlServerDriver(); } } //每个db厂商就会把这些实现类全部打包 - mysql-connector-java-8.0.25.jar //java = oracle //多态 - 面向接口编程 //---> 反射实现 --- Driver driver = XXX.getInstance();java-app[面向接口编程] J D B C [指定了很多接口] sqlserver[接口的实现] mysql[接口的实现
DriverManager[C]
sun - java.sql.DriverManager[C] - 驱动管理类,管理注册驱动.通过驱动管理类来获取DB连接
url - 不同的数据库 - url是不一样的 user - db用户名 password - db密码 public static Connection getConnection(String url, String user, String password);
关于数据库连接的url如何设置
主协议:次协议://数据库主机地址:数据库端口号/db名称?连接属性key=连接属性值
比如jdbc:mysql://localhost:3306/数据名?key1=value1&key2=value2…
常见的url的设置如下
jdbc:mysql://localhost:3306/j03s -- 高版本的需要设置useSSL=true,否则会报警告 jdbc:mysql://localhost:3306/j03s?useSSL=true -- 设置编码 jdbc:mysql://localhost:3306/j03s?useSSL=true&characterEncoding=utf-8 -- 继续设置时区 -- 世界的标准时区 - UTC -- 中国的标准时区 - Asia/Shanghai jdbc:mysql://localhost:3306/j03s?useSSL=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai
Connnection[I]
连接对象.和db进行一次会话
Statetement createStatement();//获取语句对象
PreparedStatement prepareStatement(String sql);//利用一条sql构建预编译语句对象
Statement[I]
语句对象 - 作用-负责将sql语句发送给mysql-server端进行sql编译和解释
如果发送的是dql语句,mysql-server会将查询的结果返回,封装到一个ResultSet对象中.
sun - java.sql.Statement[I]
1. int executeUpdate(String sql);//执行的是dml操作,返回的是受影响的行数 2. ResultSet executeQuery(String sql);//执行的dql操作.处理结果集对象ResultSet
ResultSet[I]
本质上一个游标-光标,默认是在标题行,在数据行的上方.比如要想取第一行的数据,应该是要将这个游标向下移动一行.
booelan next();//向下移动一行.如果下一行没有数据行了,自动返回false
int getInt(int index);//比如id列是int型,序号是从1开始的
select id,first_name fname from s_emp; rs.next(); int id = rs.getInt(1); String first_name = rs.getString(2);String getString(int index);//比如name列是varchar
int getInt(String colName);//根据列的名称去取
int id = rs.getInt("id"); String firstName = rs.getString("fname");
jdb编程步骤
加载驱动 - 加载驱动实现类 - Driver
获取连接 - 和db进行连接 - DriverManager
获取语句对象Statement
3-1. 写sql语句
3-2. 由语句对象将sql发送到mysql-server,如果执行的是DQL,还需要进行结果集处理,执行第4步
处理结果集 - 通过光标来获取表中的数据 - ResultSet
关闭对象-ResultSet,Statement,Connection
demo
package tech.aistar.day01;
import java.sql.*;
/**
* 本类用来演示: jdbc基本编程步骤 - 感受一下jdbc编程
*
* @author: success
* @date: 2021/8/25 1:34 下午
*/
public class HelloJdbcDemo {
public static void main(String[] args) {
//1. 加载驱动 - 驱动类加载到java内存中.
//但是jdbc4.0规范及其以后-加载驱动的代码可以省略不写. - 默认加载
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try {
Class.forName("com.mysql.cj.jdbc.Driver");
//2. 获取连接 - 通过DriverManager类提供的getConnection来进行获取的
//2-1. 准备三个参数
String url = "jdbc:mysql://localhost:3306/j03s?useSSL=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai";
String user = "root";
String password = "root";
conn = DriverManager.getConnection(url,user,password);
//3. 创建语句对象
st = conn.createStatement();
//作用-负责将sql语句发送给mysql-server端进行sql编译和解释
//4. 发送sql,并且由mysql-server编译执行
String sql = "select id,first_name,salary from s_emp";
//4-1. 因为执行的是DQL语句,返回一个结果集对象
rs = st.executeQuery(sql);
//5. 如果是DQL - 处理一下结果集
//结果解对象ResultSet实际上是一个光标 - 停留在标题行的上方.
//调用next方法的时候,光标就会向下移动一行.如果下方没有数据行的时候,自动返回false
while(rs.next()){
//获取查询语句中数据 - 注意一下调用的类型
//列-int->getInt方法
//列-varchar->getString方法
//列-date->getDate方法
//列-float/double->getDouble方法
//getString方法是可以获取任意类型的列的.
//根据序号取 - 查询列的序号,不是原表中的序号.
//序号从1开始
int id = rs.getInt(1);
//根据列的名称/别名 去取
String firstName = rs.getString("first_name");
double salary = rs.getDouble(3);
System.out.println(id+"\t"+firstName+"\t"+salary);
}
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
} finally {
//6. 关闭资源 - 一定要注意一下顺序.
//先关闭rs,然后是st,然后是conn
if(null!=rs){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=st){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=conn){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
ORM+OO分析
OO过程 - db设计[发现很多之前没有注意到的业务细节] - 业务中的关键对象
OO-设计表
drop table t_user;
create table t_user(
id int(7) primary key auto_increment,
username varchar(20) unique not null,
password varchar(20) not null,
birthday date
);
insert into t_user values(1,'admin','123',now());
insert into t_user values(2,'tom','123',now());
ORM
表 - 实体
主键列id 对象标识id
普通列 普通属性
外键 对象与对象之间的关系 - 对象之间是没有什么关键关系
要么关联单个对象/集合对象
int -> Integer
varchar -> String
float/double -> Double
date/datetime -> java.util.Date
public class User implements Serializable {
//实体类中的属性都是根据db设计来写的
private Integer id;
private String username;
private String password;
private Date birthday;
}
制定业务接口
IUserDao.java
public interface IUserDao { //具体的操作功能 List<User> findAll(); }
接口实现类
package tech.aistar.dao.impl;
import tech.aistar.dao.IUserDao;
import tech.aistar.model.entity.User;
import java.sql.*;
import java.util.ArrayList;
import java.util.List;
/**
* 本类用来演示: 持久层的实现类 - jdbc代码
*
* @author: success
* @date: 2021/8/25 2:17 下午
*/
public class UserDaoImpl implements IUserDao {
@Override
public List<User> findAll() {
//1. 加载驱动-省略
//2. 获取连接
Connection conn = null;
Statement st = null;
ResultSet rs = null;
List<User> users = new ArrayList<>();
try {
String url = "jdbc:mysql://localhost:3306/j03s?useSSL=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai";
String user = "root";
String password = "root";
conn = DriverManager.getConnection(url,user,password);
//3. 创建语句对象
st = conn.createStatement();
//4. 发送sql
String sql = "select * from t_user";
rs = st.executeQuery(sql);
//5. 处理结果集
while(rs.next()){
int id = rs.getInt(1);
String username = rs.getString(2);
String pwd = rs.getString(3);
Date birthday = rs.getDate(4);
//对象是数据在内存中的载体,对象 - 特殊的数组容器
User u = new User();
u.setId(id);
u.setUsername(username);
u.setPassword(password);
u.setBirthday(birthday);
users.add(u);
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
//6. 关闭资源 - 一定要注意一下顺序.
//先关闭rs,然后是st,然后是conn
if(null!=rs){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=st){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=conn){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
return users;
}
}
写单元测试junit
在项目根目录下新建一个test目录 - 右击它 - mark direcotry as - Test Sources Root
package tech.aistar.dao;
import org.junit.Test;
import tech.aistar.dao.impl.UserDaoImpl;
import tech.aistar.model.entity.User;
import java.util.List;
/**
* 本类用来演示: 针对IUserDao接口中的方法进行逐一单元测试
*
* @author: success
* @date: 2021/8/25 2:24 下午
*/
public class UserDaoTest {
IUserDao userDao = new UserDaoImpl();
@Test
public void testFindAll(){
List<User> users = userDao.findAll();
if(null!=users && users.size()>0){
users.forEach(System.out::println);
}
}
}
第一层封装
package tech.aistar.util;
import java.sql.*;
/**
* 本类用来演示: jdbc工具类
*
* @author: success
* @date: 2021/8/25 3:06 下午
*/
public class JdbcUtil {
/**
* 获取连接
* @return
*/
public static Connection getConnection() throws SQLException {
String url = "jdbc:mysql://localhost:3306/j03s?useSSL=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai";
String user = "root";
String password = "root";
Connection conn = DriverManager.getConnection(url,user,password);
return conn;
}
@SuppressWarnings("all")
public static void close(Statement st, Connection conn){
if(null!=st){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=conn){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
/**
* 释放资源
* @param rs
* @param st
* @param conn
*/
@SuppressWarnings("all")
public static void close(ResultSet rs, Statement st, Connection conn){
if(null!=rs){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=st){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if(null!=conn){
try {
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
作业
一个用户可以发布多个视频
drop table t_video; create table t_video( id int(7) primary key auto_increment, title varchar(20) not null, create_date datetime, price double(7,2), video_url varchar(120), -- 不需要创建外键约束,但是仍然需要通过user_id确定和t_user表的关系 -- Video实体类中 - private User user; -- User实体类 - private List
二进制数据存储,列的数据类型blob - binary large object - 真正的把图片,视频 - 流 -> 存储到列中 - 不可取
专门搭建一个服务器nginx - 服务器上的资源[图片/视频]都会拥有一个url[统一资源定位器 - 唯一的]
实际现在推荐的方式是在表中,比如video_url - 存储这个视频对应的它所在服务器的地址即可
基础的作业
- 完成针对t_video表的crud操作 - 交的
级联操作
IUserDao.java接口中
- 根据id删除用户,并且把这个用户下的所有的发布的视频全部删除 - 级联删除.
- 根据id查询用户,如果该用户发布了视频信息,查询这个用户下发布的视频信息 - 级联查询
- 保存一个用户的同时也保存了这个用户的三个视频信息 - 级联插入
SQL注入
负责发送sql语句的对象 - Statement语句对象 - 引发sql注入问题 - 是因为参数硬拼接到了sql语句中
sql注入的场景:
username是外部传过来的参数.该参数直接会被拼接到sql语句中.
rs = st.executeQuery(sql);
public User getByUsername(String username) { //... String sql = "select * from t_user where username='"+username+"'"; //... }
单元测试
package tech.aistar.dao;
import org.junit.Test;
import tech.aistar.dao.impl.UserDaoImpl;
import tech.aistar.model.entity.User;
/**
* 本类用来演示: sql注入
*
* @author: success
* @date: 2021/8/26 8:45 上午
*/
public class SqlInjectionTest {
IUserDao userDao = new UserDaoImpl();
@Test
public void testGetByUsername(){
// String sql = "select * from t_user where username='"+username+"'";
//username='钱枫' or '1'='1'
//此处实参是表中不存在的数据 - 钱枫
User user = userDao.getByUsername("钱枫' or '1'='1");//直接硬拼接到了sql.当然此处的字符串中也有可能包含非法的sql//语句
//select * from t_user where username='钱枫' or '1'='1';
System.out.println(user);
//User{id=1, username='admin', password='123', birthday=2021-08-25}
}
}
PrepareStatement[I]
预编译语句对象
继承于Statement对象
有效防止sql注入
如何创建预编译语句对象
PreparedStatement prepareStatement(String sql);//利用一条sql构建预编译语句对象 此处的sql可能包含一些参数的占位符 String sql="insert into t_video(title,create_date,price,video_url,user_id) values(?,?,?,?,?)"; //3-2. 创建了pst对象 // 把带有参数占位符的sql语句已经提前发送到了my-server端进行预编译好了. pst = conn.prepareStatement(sql);
如何发送参数 - 列的类型
setInt,setString,setDate,setDouble….
//把参数发送到mysql-server端,然后再由mysql-server端把参数填充到已经预编译好的sql语句 //序号也是从1开始 pst.setString(1,video.getTitle()); //pst.setDate(2,video.getCreateDate()); //关于setDate比较特殊 - java.sql.Date //但是video.getCreateDate() - java.util.Date //java.sql.Date extends java.util.Date //void setDate(int parameterIndex, java.sql.Date x) //处理 - java.util.Date -> 转换成 java.sql.Date //构造 - Date(long time);//利用毫秒数来构建一个日期对象,long->Date // long getTime();//获取日期的毫秒数;// Date->long //pst.setDate(2,new java.sql.Date(video.getCreateDate().getTime())); //java.sql.TimeStamp extends java.util.Date //提供了构造Timestamp(long time); pst.setTimestamp(2,new Timestamp(video.getCreateDate().getTime())); pst.setDouble(3,video.getPrice()); pst.setString(4,video.getVideoUrl()); //为什么需要在Video中维护了单个user对象的原因. pst.setInt(5,video.getUser().getId());方法
6-1. int executeUpate();
6-2. ResultSet executeQuery();
PrepareStatement和Statement区别
- PreparedStatement继承自Statement,都是接口
- Statement适用于运行静态 SQL 语句[参数直接硬拼接到sql语句]。 Statement 接口不接受参数。
- **PrepareStatement计划多次使用同一条 SQL 语句[适合执行同构的sql]**, PreparedStatement接口运行时接受输入的参数。
- PrepareStatement有效防止sql注入
- PreparedStatement会预编译SQL语句,Statement每次都会解析/编译SQL
- preStatement 的效率 比 Statement 的效率高
同构sql的场景
PrepareStatement
String sql="insert into t_video(title,create_date,price,video_url,user_id) values(?,?,?,?,?)";
//提前把sql发送mysql-server预编译
pst = connection.prepareStatement(sql);
//发送参数
for (Video video : videoList) {
//一组参数
//设置参数
pst.setString(1,video.getTitle());
pst.setTimestamp(2,new Timestamp(video.getCreateDate().getTime()));
pst.setDouble(3,video.getPrice());
pst.setString(4,video.getVideoUrl());
//为什么需要在Video中维护了单个user对象的原因.
pst.setInt(5,video.getUser().getId());
//发送
pst.executeUpdate();
}
Statement实现
st = conn.createStatement();
for (Video video : videoList) {
String sql = "insert....字符串拼接.."+video.getTitle()+"','"+video.get...;
//Statement每次都会解析/编译SQL
st.executeUpdate(sql);
}
批处理操作
比如批量插入 - 即使以后学习了持久层的框架[hibernate,mybatis,mybatis-plus,springdatajpa],但是遇到批量插入,首选的技术jdbc
.效率仍然是最高的.
PrepareStatement关于批处理的api
- void addBatch();向这个 PreparedStatement对象的一批命令添加一组参数
- void clearParameters() 立即清除当前参数值。
- void clearBatch();//清空此
Statement对象的当前SQL命令列表- int[] executeBatch();//执行命令列表
需要在url上增加一个配置&rewriteBatchedStatements=true
@Override public void saveListBatch(List<Video> videoList) { Connection connection = null; PreparedStatement pst = null; int count = 0; try { connection = JdbcUtil.getConnection(); //无论保存多少给视频信息,使用到的是相同的结构的 - 同构的sql语句 String sql="insert into t_video(title,create_date,price,video_url,user_id) values(?,?,?,?,?)"; //提前把sql发送mysql-server预编译 pst = connection.prepareStatement(sql); //发送参数 for (Video video : videoList) { //一组参数 //设置参数 pst.setString(1,video.getTitle()); pst.setTimestamp(2,new Timestamp(video.getCreateDate().getTime())); pst.setDouble(3,video.getPrice()); pst.setString(4,video.getVideoUrl()); //为什么需要在Video中维护了单个user对象的原因. pst.setInt(5,video.getUser().getId()); //发送 //缺陷 - 来一个对象 - 一组参数 - 客户端[jdbc代码]-频繁和mysql-server端进行交互 - 发送一组参数 //pst.executeUpdate(); //优化 - 同时发送很多组. //可以把每个组的参数 - 放入到批处理的列表中. //向这个 PreparedStatement对象的一批命令添加一组参数 pst.addBatch();//意味着此时没有进行发送 count++;//计数 - 组 //应该每多少组 - 就得发送一次呢 - 根据具体的业务. if(count==1000){ //把参数发送mysql-server端一次 pst.executeBatch();//执行批处理的命令列表 //清空一下命令列表 pst.clearBatch(); pst.clearParameters();//立即清除当前参数值。 count=0; } } //考虑插入的不是1000的倍数 if(count!=0){ //防止漏电了参数 pst.executeBatch(); pst.clearBatch(); pst.clearParameters(); } } catch (SQLException e) { e.printStackTrace(); }finally { JdbcUtil.close(pst,connection); } }
第二层封装
- 老管说的话,一定都是对的
- 如果发现老管说错了,请参考第一条.
模板设计模式
Connection connection = null;
PreparedStatement pst = null;
try {
//1.加载驱动,获取连接
connection = JdbcUtil.getConnection();
//个性的
//String sql="";
//pst = connection.prepareStatement(sql);
pst.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
}finally {
JdbcUtil.close(pst,connection);
}
JdbcTemplate - 自定义jdbc模板工具类
idea配置datasource
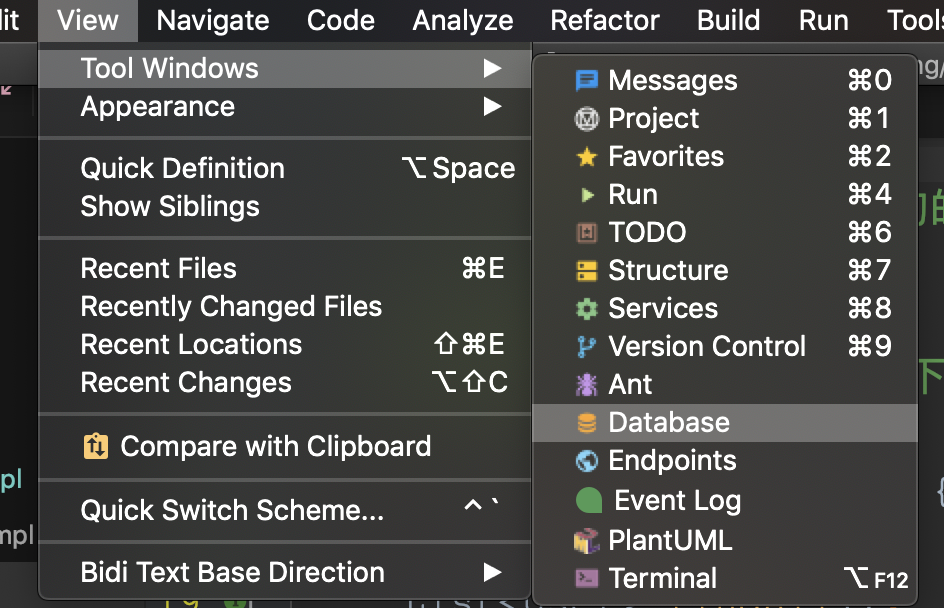
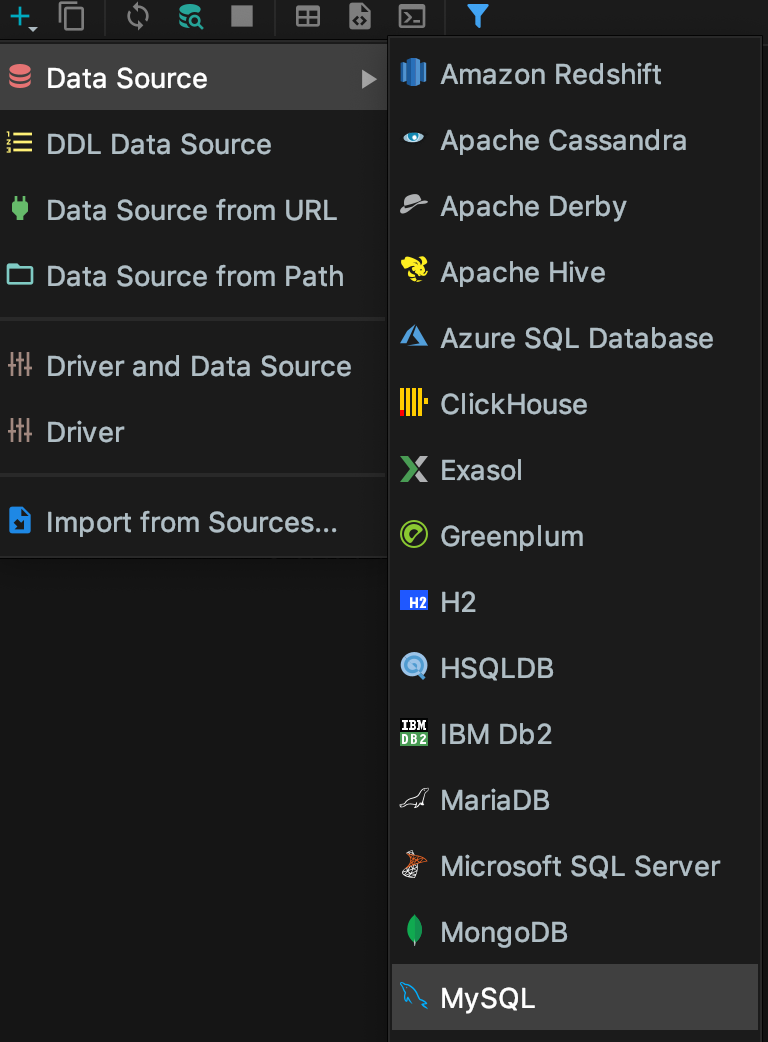
选择驱动
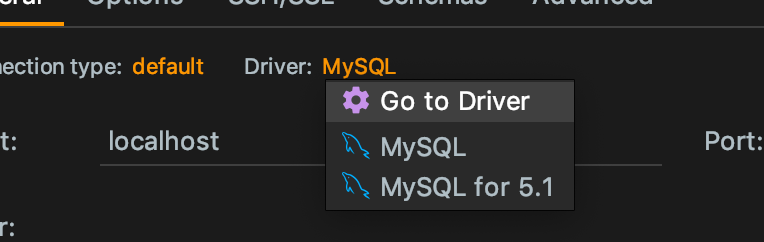
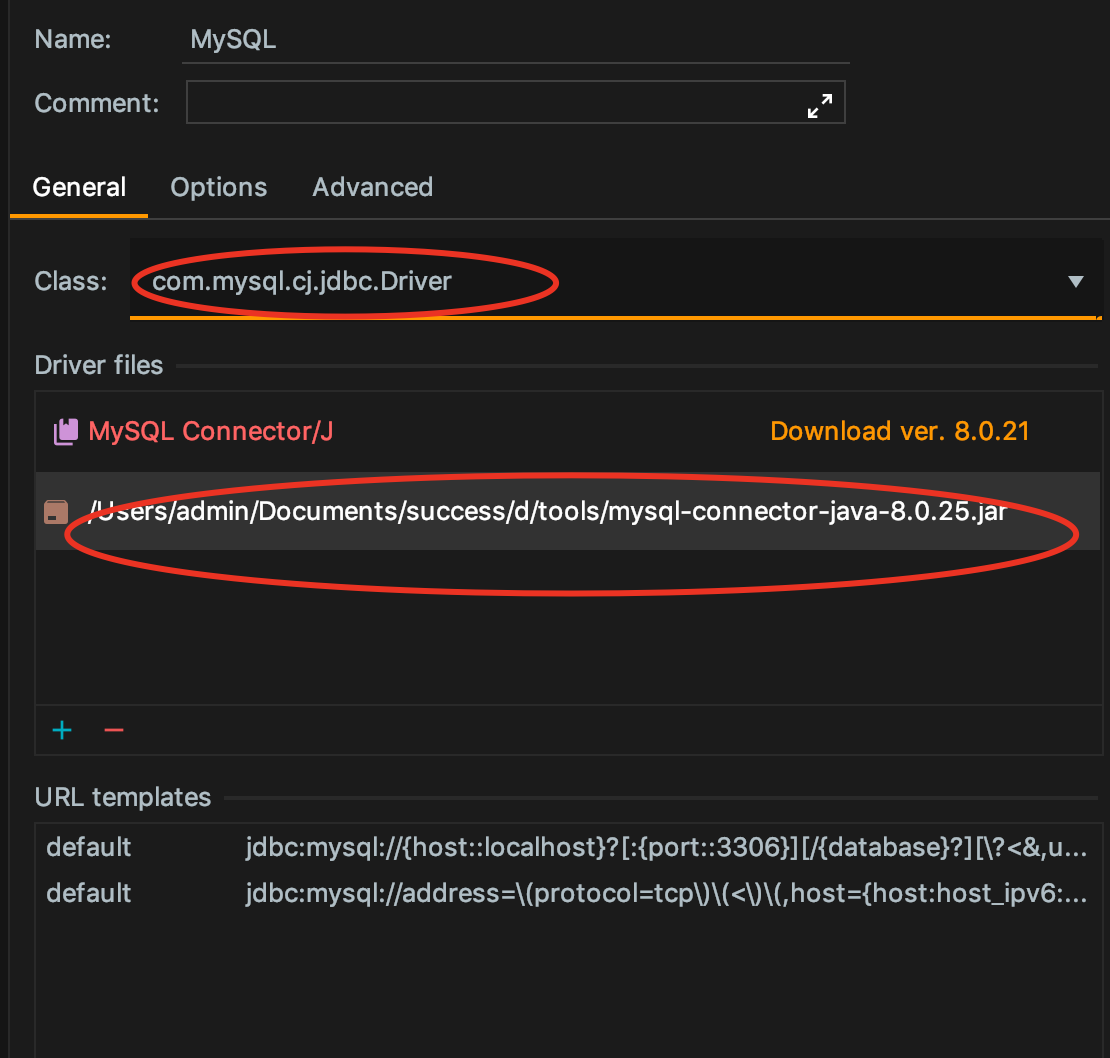
点击apply
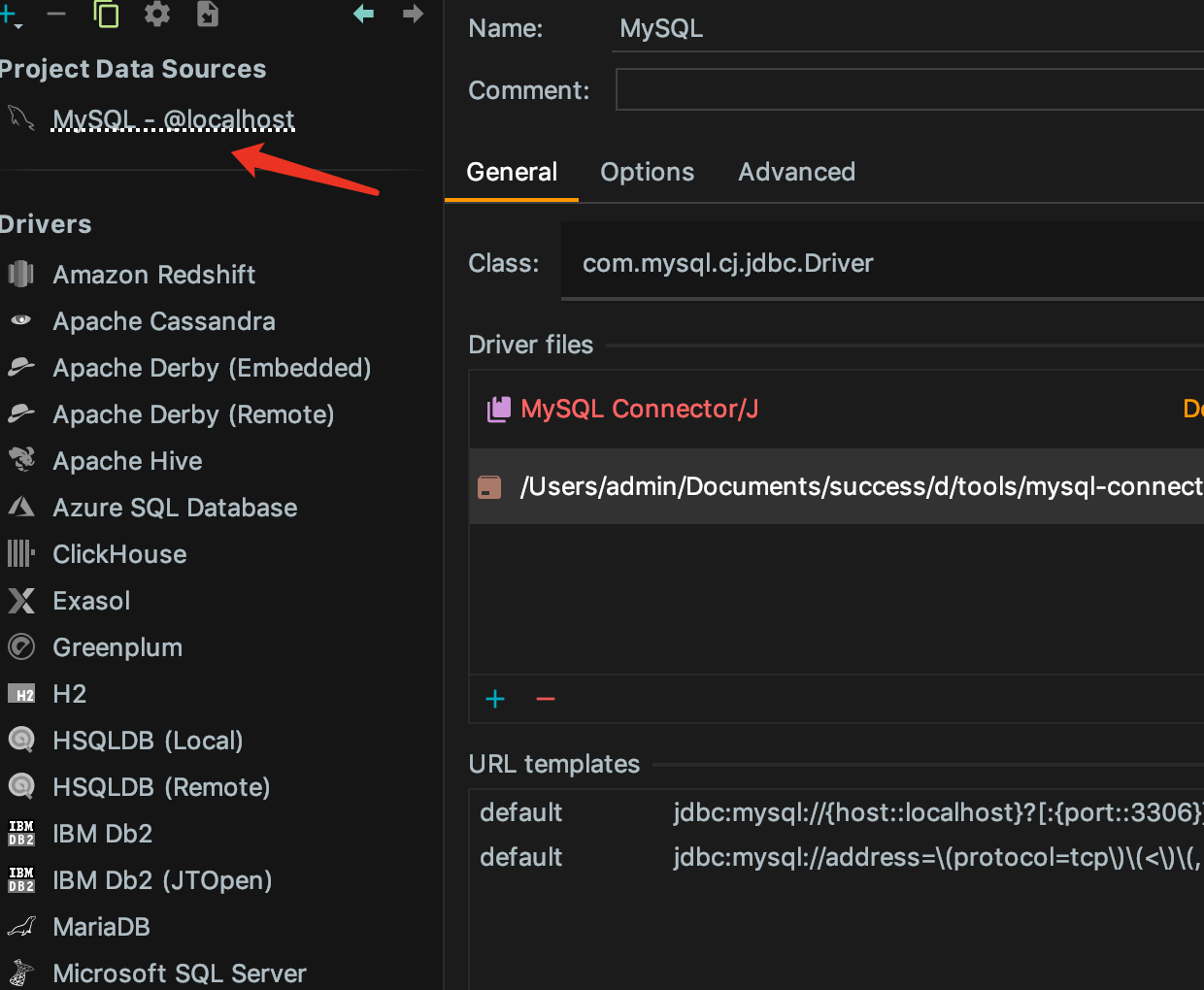
db-连接属性
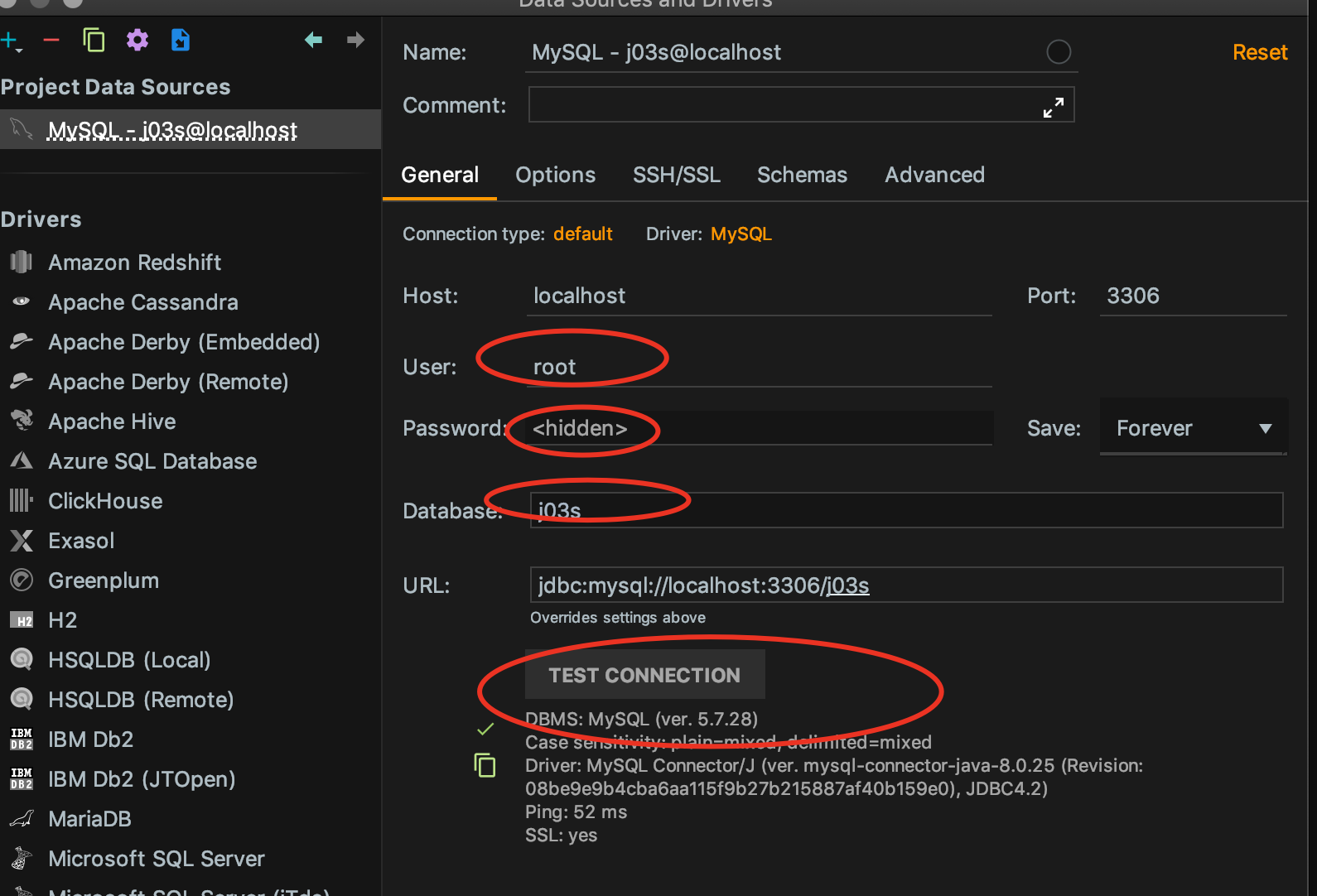
如果不行
级联插入
插入一个用户的同时,同时插入这个用户的视频信息 - 业务线是不存在.
如果视频信息比较多 - 批处理
事务 - 同时成功和同时失败
插入user的时候,怎么拿到刚刚插入的那个主键值[auto_increment]
//为了拿到自增长的主键列的值 pst = conn.prepareStatement(sql,Statement.RETURN_GENERATED_KEYS); //插入一个新的user之后,如何能够拿到刚刚自增长的主键列的值 //一行一列的 rsPk = pst.getGeneratedKeys();//肯定是拿到一个 Integer insertUserId = null; if(rsPk.next()){ insertUserId = rsPk.getInt(1); }
事务
jdbc的事务是和底层的数据是相关的相关的.
jdbc中的事务是默认自动提交的.
jdbc编程中的事务 - 编程性事务 - 控制事务的代码和jdbc代码耦合在一块儿.
未来都是使用的是spring中声明事务.把事务的代码和应用程序的代码分离了.
Connection conn = null; PreparedStatement pst = null; try { conn = JdbcUtil.getConnection(); //保证同时成功同时失败 //涉及到很多个sql - 保证事务的原子性 - 同时成功,同时失败. //设置手动提交 conn.setAutoCommit(false);//默认是自动提交的 //手动提交 conn.commit(); } catch (SQLException e) { //回滚 if(null!=conn){ try { conn.rollback();//回滚 } catch (SQLException ex) { ex.printStackTrace(); } } e.printStackTrace(); }finally { JdbcUtil.close(pst,conn); }
作业
IUserDao.java
统计每个用户发布的视频的数量
UserDaoImpl.java实现类不要给我写输出语句 - 返回结果.
今天代码级联操作 - 理解+敲
多条件组合分页查询
2-1. 如果仅仅给定了一个用户名 - 根据用户名进行一个分页查询
2-2. 如果仅仅给定了一个title,那么就是根据title进行模糊分页查询
2-2. 如果username和title同时给了.同时根据这俩个条件[同时成立]进行分页查询.
2-3. 如果俩个条件都不给.那么就是查整个视频表,分页查询.
DTO
DTO - Data transfer object - 数据传输对象.
当内存中的数据没有任何一个实体类可以绑定的时候,那么可以考虑创建第三方实体类,用来作为数据交互的容器 - DTO
DTO对象它是不需要和表和它进行映射的,它只是在内存中进行传输的.
多条件组合分页查询
使用limit语句 - 分页公式:limit (pageNow-1)*pageSize,pageSize
分页之后得到的数据
每页显示的条数 - 手动传入的.
根据条件查询得到的结果的个数 - rows - 总的条数
总的条数/每页显示条数 => 总的页数
网页中显示的分页的数据-[手机信息,book信息]
上一页 1 2 3 4 5 6 7 8 下一页 当前页12/30总页
业务逻辑层 - service
数据持久层 - dao - dao接口 - 只负责和db进行交互 - sql语句 - 关注点在”db和数据的crud”
业务逻辑层 - service - service接口 - 不需要和db进行交互,把dao层交互得到的数据进行业务逻辑的处理 - 不需要写sql
service层需要调用dao层 - service关注点 - “业务逻辑”
最难写的一层就是service层
元数据
DataBaseMetaData - 数据库的元数据 - 可以获取数据库的元信息 - url,user,driver,版本号等信息
java.sql.Connection提供的 DataBaseMetaData getMetaData();ResultSetMetaData - 结果集元数据 - 可以获取结果集的元信息
package tech.aistar.day03; import tech.aistar.util.JdbcUtil; import java.sql.*; /** * 本类用来演示: 结果集元数据 * * @author: success * @date: 2021/8/27 10:48 上午 */ public class ResultSetMetaDataDemo { public static void main(String[] args) { Connection conn = null; PreparedStatement pst = null; ResultSet rs = null; try { conn = JdbcUtil.getConnection(); String sql = "select id,title from t_video"; //可以生成可滚动和/或可更新的ResultSet对象 pst = conn.prepareStatement(sql); //本质上是一个光标,默认是停留在第一行的上方. rs = pst.executeQuery(); //描述结果集的 - 结果集的元数据[描述数据的数据] ResultSetMetaData rsmd = rs.getMetaData(); //1. 获取查询结果 - 列的个数 int cols = rsmd.getColumnCount(); for (int i = 1; i <=cols; i++) { //获取列的标题名称 - 下标从1开始 String colName = rsmd.getColumnName(i); System.out.print(colName+"\t"); } System.out.println(); while(rs.next()){ //String getString(int i);//可以获取任意类型的数据 for (int i = 1; i <=cols; i++) { System.out.print(rs.getString(i)+"\t"); } System.out.println(); } } catch (SQLException e) { e.printStackTrace(); }finally { JdbcUtil.close(rs,pst,conn); } } }
重新认识ResultSet
构建一个可滚动可更新的结果集对象
- 任意定位到具体的行
- 直接使用rs对象来进行update和delete以及insert操作
本质上是一个光标,默认是停留在第一行的上方.
- boolean next();//向下移动一行
- boolean absolute(int row);//绝对定位到行
- boolean first();//定位到第一行
- boolean last();//定位到最后一行
- boolean relative(int n);//相对定位
demo
package tech.aistar.day03;
import tech.aistar.util.JdbcUtil;
import javax.xml.transform.Result;
import java.sql.*;
/**
* 本类用来演示: 结果集对象
*
* @author: success
* @date: 2021/8/27 10:34 上午
*/
public class ResultSetDemo {
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pst = null;
ResultSet rs = null;
try {
conn = JdbcUtil.getConnection();
String sql = "select * from t_video";
//可以生成可滚动和/或可更新的ResultSet对象
pst = conn.prepareStatement(sql, ResultSet.TYPE_SCROLL_INSENSITIVE,ResultSet.CONCUR_UPDATABLE);
//本质上是一个光标,默认是停留在第一行的上方.
rs = pst.executeQuery();
//绝对定位 - 默认是不支持的
//Operation not allowed for a result set of type
//ResultSet.TYPE_FORWARD_ONLY -
//默认的只有一个向前移动的光标。
//因此,您只能从第一行到最后一行迭代一次。 可以生成可滚动和/或可更新的ResultSet对象
rs.absolute(3);//设置成一个可滚动的结果集
//相对定位
//rs.relative(-2);
//rs.first();//定位到第一行
//rs.last();//定位到最后一行
//可以直接通过光标来进行update操作和delete操作
//更新第3行的title - rs.absolute(3)
//rs.updateString("title","田原");
//commit操作
//rs.updateRow();
//删除行
rs.deleteRow();
System.out.println(rs.getString(2));
} catch (SQLException e) {
e.printStackTrace();
}finally {
JdbcUtil.close(rs,pst,conn);
}
}
}
数据库连接池
DriverManager方式缺陷
在执行JDBC的增删改查的操作时,如果每一次操作都来一次打开连接,操作,关闭连接,
那么创建和销毁JDBC连接的开销就太大了。为了避免频繁地创建和销毁JDBC连接,我们可以通过连接池(Connection Pool)复用已经创建好的连接。
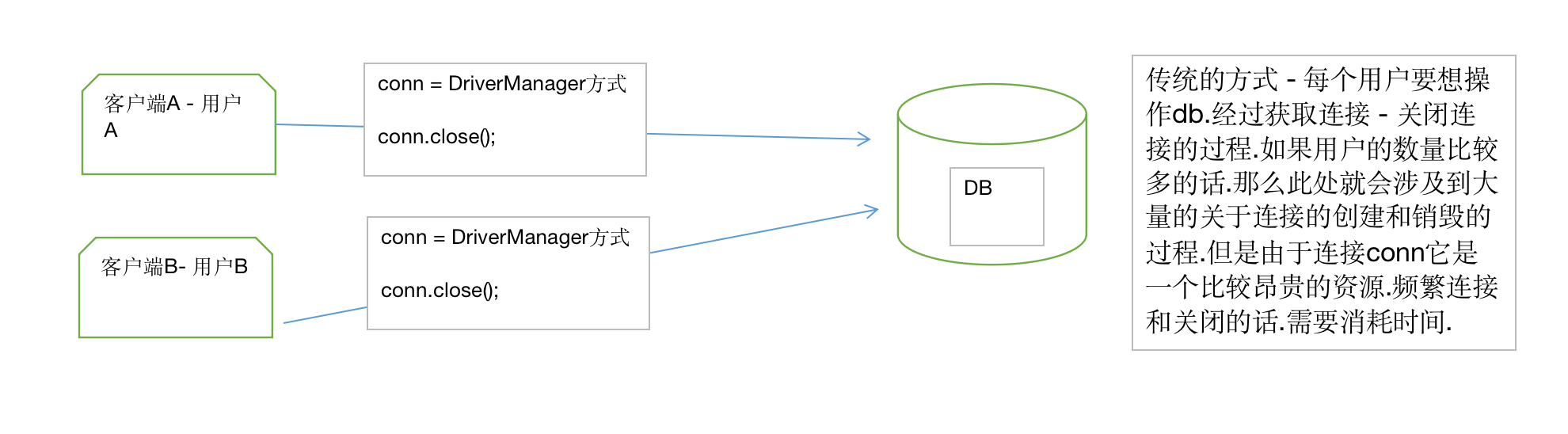
连接池选择
JDBC连接池有一个标准的接口
javax.sql.DataSource,注意这个类位于Java标准库中,但仅仅是接口。要使用JDBC连接池,我们必须选择一个JDBC连接池的实现。常用的JDBC连接池有:
- HikariCP
- C3P0
- BoneCP
- Druid - 阿里的
- dbcp
连接池的基本原理
数据库连接池的基本思想就是为数据库连接 建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。我们可以通过设定 连接池最大连接数来防止系统无尽的与数据库连接。更为重要的是我们可以通过连接池的管理机制监视数据库的连接的数量?使用情况,为系统开发?测试及性能调 整提供依据。
连接池的工作原理
连接池的工作原理主要由三部分组成,分别为连接池的建立、连接池中连接的使用管理、连接池的关闭。
连接池的创建
一般在系统初始化时,连接池会根据系统配置建立,并在池中创建了几个连接对象,以便使用时能从连接池中获取。
连接池中的连接不能随意创建和关闭,这样避免了连接随意建立和关闭造成的系统开销。Java中提供了很多容器类可以方便的构建连接池,例如Vector[线程安全的类]、Stack等。连接池连接的使用管理
连接池管理策略是连接池机制的核心,连接池内连接的分配和释放对系统的性能有很大的影响。其管理策略是:
当客户请求数据库连接时,首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;如果达到就按设定的最大等待时间进行等待,如果超出最大等待时间,则抛出异常给客户。 当客户释放数据库连接时,先判断该连接的引用次数是否超过了规定值,如果超过就从连接池中删除该连接,否则保留为其他客户服务。该策略保证了数据库连接的有效复用,避免频繁的建立、释放连接所带来的系统资源开销。当应用程序退出时,关闭连接池中所有的连接,释放连接池相关的资源,该过程正好与创建相反
为什么要使用连接池
数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。 一个数据库连接对象均对应一个物理数据库连接,每次操作都打开一个物理连接,使用完都关闭连接,这样造成系统的 性能低下。 数据库连接池的解决方案是在应用程序启动时建立足够的数据库连接,并讲这些连接组成一个连接池(简单说:在一个“池”里放了好多半成品的数据库联接对象),由应用程序动态地对池中的连接进行申请、使用和释放。对于多于连接池中连接数的并发请求,应该在请求队列中排队等待。并且应用程序可以根据池中连接的使用率,动态增加或减少池中的连接数。 连接池技术尽可能多地重用了消耗内存地资源,大大节省了内存,提高了服务器地服务效率,能够支持更多的客户服务。通过使用连接池,将大大提高程序运行效率,同时,我们可以通过其自身的管理机制来监视数据库连接的数量、使用情况等。
相关配置-部分
maxActive 连接池支持的最大连接数,这里取值为20,表示同时最多有20个数据库连接。一般把maxActive设置成可能的并发量就行了设 0 为没有限制。
maxIdle 连接池中最多可空闲maxIdle个连接 ,这里取值为20,表示即使没有数据库连接时依然可以保持20空闲的连接,而不被清除,随时处于待命状态。设 0 为没有限制。
minIdle 连接池中最小空闲连接数,当连接数少于此值时,连接池会创建连接来补充到该值的数量
initialSize 初始化连接数目
maxWait 连接池中连接用完时,新的请求等待时间,毫秒,这里取值-1,表示无限等待,直到超时为止,也可取值9000,表示9秒后超时。超过时间会出错误信息
手撸连接池
代理模式
静态代理
动态代理 - jdk动态代理[Spring底层默认的代理模式]以及cglib代理
jdk动态代理只能代理接口
需求
给dao层中的每个方法添加日志输出.
不使用代理
package tech.aistar.proxy.demo01;
import java.util.Date;
/**
* 本类用来演示:
//日志记录是与业务无关的代码
//1. 业务无关代码和业务相关代码耦合在一块儿.造成dao层/service层方法比较臃肿
//2. 日志有一定的格式.如果哪天日志格式,日志记录的内容发生了改变.需要修改所有
// 出现日志的程序代码的.
//3. 日志记录的功能维护性比较差
*
* @author: success
* @date: 2021/8/27 2:19 下午
*/
public class TeacherDaoImpl implements ITeacherDao{
@Override
public void save() {
//与业务无关的方法 - 日志记录 - 核心方法调用之前日志输出
System.out.println("log-before..."+new Date());
//核心"业务"的代码
System.out.println("jdbc-insert");
//日志记录 - 核心方法调用之后日志输出
System.out.println("log-after..."+new Date());
}
@Override
public int delById(Integer id) {
System.out.println("log-before..."+new Date());
//核心"业务"的代码
System.out.println("jdbc-del:"+id);
System.out.println("log-after..."+new Date());
return 0;
}
}
静态代理
在程序的编译期间,手动编写静态代理类 => 并且在编译期就得生成这个静态代理类.
优点:将核心的代码和非核心的代码[日志代码]进行了分离.不会导致核心的代码显示得比较臃肿了.
缺点
程序中会出现大量的静态代理类[增加了维护成本].
如果日志格式需要改变.需要修改很多静态代理类中的代码的.对于静态代理类而言的.违背了软件的”开闭原则”.
被代理对象 - 房东
代理对象 - 中介
代理对象和被代理对象都应该去实现同一个接口 - 在实际应用的时候,是使用代理对象去调用接口的方法!
package tech.aistar.proxy.demo02;
import java.util.Date;
/**
* 本类用来演示: 编译期间生成的一个静态代理类
*
* 代理对象和被代理对象都应该去实现同一个接口
*
*
* @author: success
* @date: 2021/8/27 2:28 下午
*/
public class TeacherDaoImplProxy implements ITeacherDao{
private ITeacherDao teacherDao;
public TeacherDaoImplProxy(){
//构建一个代理对象的时候,里面会立即初始化被代理的对象类[原始对象]
this.teacherDao = new TeacherDaoImpl();
}
@Override
public void save() {
//"中介卖房的时候吹牛的话"
System.out.println("log-before"+new Date());
teacherDao.save();//原始对象的核心的业务
System.out.println("log-after"+new Date());
}
@Override
public int delById(Integer id) {
System.out.println("log-before"+new Date());
teacherDao.delById(10);//原始对象的核心的方法
System.out.println("log-after"+new Date());
return 0;
}
}
动态代理
- 不需要在编译期间手动编写代理类.
- 是在程序的运行期间,反射创建代理对象.
- jdk动态代理技术只能代理接口.
- 总结:使用代理对象去调用方法应该是比你原始对象去调用方法的功能更加强大.
package tech.aistar.proxy.demo03; import java.lang.reflect.InvocationHandler; import java.lang.reflect.Method; import java.util.Date; import java.util.Properties; /** * 本类用来演示: 动态代理 - 代理任何接口的 * * @author: success * @date: 2021/8/27 2:48 下午 */ public class ProxyHandler implements InvocationHandler { //jdk动态代理技术只能代理接口 private Object obj;//被代理的原始对象 public ProxyHandler(Object obj){ this.obj=obj; } /** * invoke方法何时被调用? * 当使用代理对象调用被代理对象中的方法的时候[save,del] * 会自动执行invoke方法. * * 如果调用的是ITeacherDao接口中的save方法 * proxy -> 该接口的代理 * method -> save方法对应的反射的Method实例 * * @param proxy 程序在运行的过程中生成的那个代理对象 * @param method 当前正在调用的接口中的那个方法对应的反射的Method实例 * @param args 被调用的方法的参数 * @return * @throws Throwable */ @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { System.out.println("log-before"+new Date()); //反射调用方法 Object result = method.invoke(obj,args); System.out.println("log-after"+new Date()); return result; } }
使用第三方连接池
连接池[实现类]本身就是jdk提供的java.sql.DataSource接口的具体的实现类[BasicDataSource].
连接池本身就是属于一个昂贵的重量级的对象,不要轻易去关闭它.
整个应用程序中,一个连接池对应一个db数据库 - 连接池叫做数据源.保证连接池的单例.
步骤
导入jar
连接池的配置文件 - 配置参数建议是放在配置文件中统一进行管理的.
db.properties
# 系统初始化的时候,连接池中的可用的连接的初始的个数 initialSize=3 # 连接池中最小空闲连接数,当连接数少于此值时,连接池会创建连接来补充到该值的数量 minIdle=5 # 连接池中最多可空闲maxIdle个连接 , # 这里取值为20,表示即使没有数据库连接时依然可以保持20空闲的连接, # 而不被清除,随时处于待命状态。设 0 为没有限制。 maxIdle=15 # 连接池支持的最大连接数, maxActive=15 # 连接池中连接用完时,新的请求等待时间,毫秒 # 1. 当新的请求到达,并且连接池中的连接已经到达maxActive值,连接池是不会分配连接给这个用户的. # 那么这个用户就会在等待队列中[等待有没有被使用的连接被释放出来 - 新的空闲连接] # 如果超过maxWait -> 抛出一个已经超时的错误. maxWait=5000
编写连接池类 - > 单例的.
package tech.aistar.util; import org.apache.commons.dbcp.BasicDataSource; import java.sql.Connection; import java.sql.SQLException; /** * 本类用来演示: 连接池[俩个jar]设置参数而已 * * @author: success * @date: 2021/8/27 3:51 下午 */ public class PoolUtil { private static volatile PoolUtil instance = null; private BasicDataSource basicDataSource; private PoolUtil(){ //进行一些连接池的配置 basicDataSource = new BasicDataSource(); basicDataSource.setUrl("jdbc:mysql://localhost:3306/j03s?useSSL=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true"); basicDataSource.setUsername("root"); basicDataSource.setPassword("root"); //设置参数 basicDataSource.setInitialSize(Integer.valueOf(DBPropUtil.getValue("initialSize"))); basicDataSource.setMinIdle(Integer.valueOf(DBPropUtil.getValue("minIdle"))); basicDataSource.setMaxIdle(Integer.valueOf(DBPropUtil.getValue("maxIdle"))); basicDataSource.setMaxActive(Integer.valueOf(DBPropUtil.getValue("maxActive"))); basicDataSource.setMaxWait(Long.valueOf(DBPropUtil.getValue("maxWait"))); } public static PoolUtil getInstance(){ if(null==instance){ synchronized (PoolUtil.class){//"类锁" if(null==instance){ instance = new PoolUtil(); } } } return instance; } /** * 获取连接 * @return */ public Connection getConnection() throws SQLException { return basicDataSource.getConnection(); } }使用连接池来获取连接
conn = PoolUtil.getInstance().getConnection(); //拿到的是一个Connection接口的代理对象 //class org.apache.commons.dbcp.PoolingDataSource$PoolGuardConnectionWrapper //conn.getClass(); //原始对象conn.close();//销毁掉了... conn.close();//关闭 //代理对象在调用close();//自动执行invoke方法 //method - close方法的Metthod实例 //proxy - conn @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { //到底是应该销毁还是应该把这根连接放回到连接池中,让别的请求继续使用呢??? // return result; }
DB设计之后
mybatis框架 - 进入到前端 - 设计项目页面了.
组长分配任务 - > 组员 - > 写sql脚本
- DDL - 建表语句
- Insert语句 - 模拟数据 - 尽量真实.
jdbc拓展
复习反射技术+动态代理
实体类的设计+业务层service
为学习mybatis作一个铺垫.
强调下项目中鼓励使用单表查询
jdbc缺陷
涉及到查询语句 - 手动封装的过程 - 麻烦
持久层的框架 - Hibernate全自动的ORM框架 - 可以实现完全的自动封装的过程.
Mybatis半自动的ORM框架 - 查询的结果 - 有的需要手动封装,有的可以自动封装.
框架 - 为了解决某一领域里的问题而提供的一套解决方案.
sql语句会硬编码到了程序中了.java代码和sql语句耦合在一块儿了.不利于后期的sql语句的优化
如果后期需要对sql进行优化,还需要对java代码重新编译 - 重新打包 - 重新部署.
实体类的设计
开发中严格按照这个要求.
- 表名要么就和类名保持一致,要么就使用统一的前缀.
- 列名-属性名高度保持一致-全部小写以及多个单词一定采用匈牙利命名xxx_yyy_zzz
尤为重要的 - 对象之间的关系不再是采用之前的那样的强耦合的关系呢!
案例
drop table t_user;
create table t_user(
id int(7) primary key auto_increment,
username varchar(20) unique not null,
password varchar(20) not null,
birthday date
);
insert into t_user values(1,'admin','123',now());
insert into t_user values(2,'tom','123',now());
drop table t_video;
create table t_video(
id int(7) primary key auto_increment,
title varchar(20) not null,
create_date datetime,
price double(7,2),
video_url varchar(120),
user_id int(7)
);
insert into t_video values(1,'娱乐圈需要整顿',now(),10.0,'http://aistar/001.mp4',1);
insert into t_video values(2,'双减计划',now(),20.0,'http://aistar/002.mp4',1);
insert into t_video values(3,'鼓励三胎',now(),30.0,'http://aistar/003.mp4',2);
insert into t_video values(4,'鼓励一妻多夫',now(),40.0,'http://aistar/004.mp4',1);
实体类设计
public class User{
private Integer id;
private String username;
private String password;
private Date birthday;
//不需要进行视频信息的集合的维护...
}
public class Video{
private Integer id;
private String title;
private Date createDate;
private Double price;
private String videoUrl;
//表中的外键是什么,此处就写什么.
private Integer userId;
}
// TODO... 对象之间的绑定操作应该如何进行???
需求
根据用户的id查询用户信息,如果该用户具有视频信息一并加载出来
根据id级联删除之前级联操作
- 方式一:使用了嵌套查询-在dao层的一个方法中写了俩条sql.
- 方式二:在dao层的一个方法中写了一个关联查询.
绑定的代码-user.setVideoList(videos);
实际的开发中尽量不要多表查询.如果出现三个表关联查询 - 性能低下了.
每条sql语句可以被灵活的去复用了.
分表操作 - 单表有利于后期的维护的.
单表的解决方案
先根据用户id查询出用户出来
根据用户id[user_id]去查询视频表
需要使用第三方dto对象来建立User和Video的一个关系.
//UserVo-绑定用户和这个用户的视频信息的. //第一种方式 - 采用继承的写法 - 不推荐使用继承的. public class UserVo extends User { private List<Video> videoList; } //第二种方式 public class UserVo { private User user; private List<Video> videoList; }
- 制定业务层接口 - 数据的绑定
回顾动态代理
jdk动态代理只能代理接口.
package tech.aistar.proxy.demo03;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.util.Date;
import java.util.Properties;
public class ProxyHandler implements InvocationHandler {
private Object obj;
public ProxyHandler(Object obj){
this.obj=obj;
}
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//proxy - teacherDao对应的代理对象
//method-代理对象正在调用的那个方法的method实例,del - Method m = c.getDeclaredMethod("del");
System.out.println("log-before"+new Date());
//反射调用方法
Object result = method.invoke(obj,args);//核心的业务.原始obj
System.out.println("log-after"+new Date());
return result;
}
}
//单元测试
//jdk动态代理只能代理接口.
ITeacherDao teacherDao = new TeacherDaoImpl();
ProxyHandler hander = new ProxyHandler(teacherDao);
//构建代理对象
ITeacherDao proxy = (ITeacherDao) Proxy.newProxyInstance(teacherDao.getClass().getClassLoader()
,teacherDao.getClass().getInterfaces(),hander);
//代理对象调用目标接口中的方法
proxy.del(10);//invoke方法
proxy.save();
//总结出来就是
//代理对象去调用原始接口中的目标方法的时候,自动执行invoke方法
//invoke方法中除了核心的方法的调用[反射],还有可能有额外的动作.
手撸连接池
Connection - 接口 - 才可以使用jdk动态代理技术
目标方法 - commit(),close();
connProxy - conn连接对象的代理对象
核心的业务方法conn.close();
connProxy.close();//自动调用invoke - 判断,到底是应该把连接销毁conn.close();还是应该把这根连接进行回收,放回到连接池中.
原始对象 - 房东
- 租房
- 卖房
代理对象 - 中介
客户访问房源 - 调用 - [中介吹牛1,吹牛2,吹牛3 , 房东的.房子[反射调用] , ......] - invoke
package tech.aistar.mypools;
import tech.aistar.util.JdbcUtil;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.LinkedList;
/**
* 本类用来演示: 简化的连接池
*
* @author: success
* @date: 2021/8/30 3:10 下午
*/
public class MyDataSource {//单例的
//最大的连接
public int maxActive = 8;
//初始化的连接数量
public int initialSize = 3;
//正在被使用的连接
public int currSize = 0;
//"连接池" - 集合实现的.
//重量级的对象 - 只要被加载一次,并且整个内存中的实例只有1个.
// 不能随意创建和销毁 - 比较耗时.
public LinkedList<Connection> pools = new LinkedList<>();
private static volatile MyDataSource instance = null;
//私有化构造
private MyDataSource(){
//初始化一些拥有的连接放入到"连接池中去"
for (int i = 0; i < initialSize; i++) {
pools.add(createConnection());
}
}
public static MyDataSource getInstance(){
if(null==instance){
synchronized (MyDataSource.class){
if(null==instance){
instance = new MyDataSource();
}
}
}
return instance;
}
public Connection createConnection(){
//jdbc代码...
//代理对象
Connection connProxy = null;
try {
Connection conn = JdbcUtil.getConnection();//原始接口
//conn的代理对象
connProxy = (Connection) Proxy.newProxyInstance(conn.getClass().getClassLoader(), conn.getClass().getInterfaces(), new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//只要使用代理对象调用目标接口Connection接口的任何方法-都会执行invoke
//close,commit,rollback ....
Object result = null;
//改变close方法的功能 - 未必是直接销毁conn,有可能是放回到pools中
if("close".equals(method.getName()) && currSize<=maxActive){
System.out.println("===放回到连接池中===");
currSize--;//当前正在被使用到的连接
pools.add(conn);
}else if("close".equals(method.getName()) && currSize>maxActive){
//initialSize - 最大的空闲
System.out.println("===真正的去销毁连接===");
currSize--;
if(null!=conn){
conn.close();
}
}else{
//commit,rollback...
result = method.invoke(conn,args);
}
return result;
}
});
} catch (SQLException e) {
e.printStackTrace();
}
//返回的是代理对象
return connProxy;
}
//提供一个方法来获取连接
//目的 - 从连接池中得到一根连接
public Connection getConnection(){
//1. 如果连接池中有可能的连接,那么就直接从"pools"中直接返回一个
//2. 保证多线程环境下,不能有俩个线程争抢到同一个connection
synchronized (pools){
if(pools.size()>0){
System.out.println("===直接从pools中取===");
currSize++;
//说明连接池中有可用的连接
//集合中删除一个,删除的这个连接返回出去
return pools.removeLast();
}else if(currSize<=maxActive){
System.out.println("===init初始化的连接已经用完了===");
//pools中初始的连接已经用光了.
currSize++;
//隐含的条件 - 拿到之后.需要把这根连接放连接池中 - 有可能.
return createConnection();
}else{
throw new RuntimeException("sorry,您需要等待了!已经超过连接池最大活动数了!");
}
}
}
public static void main(String[] args) throws SQLException {
Connection conn1 = MyDataSource.getInstance().getConnection();
Connection conn2 = MyDataSource.getInstance().getConnection();
Connection conn3 = MyDataSource.getInstance().getConnection();
//代理对象调用 - 放回到连接池中
Connection conn4 = MyDataSource.getInstance().getConnection();
conn4.close();
// conn3.close();
System.out.println("当前正在使用的连接的个数:"+MyDataSource.getInstance().currSize);
System.out.println("当前连接池中存在的可用的连接的个数:"+MyDataSource.getInstance().pools.size());
//System.out.println(MyDataSource.getInstance().pools.size());
//conn1.close();//不能直接傻瓜式去关闭了,也有可能是放回到连接池中.
//conn1.close();//自动找到invoke方法
// conn1.setAutoCommit(false);
//
// conn1.commit();
}
}



