Map[I]
HashMap[C]
数据存储的形式是key-value,针对key是无序不可重复的.
jdk8.x之前,底层的数据结构是桶数组+链表
jd8.0开始,底层的数据结构是桶数组+链表+红黑树
桶(哈希桶)数组 - 里面的元素放在数组的这个位置是通过一个哈希算法计算得到的.
图示
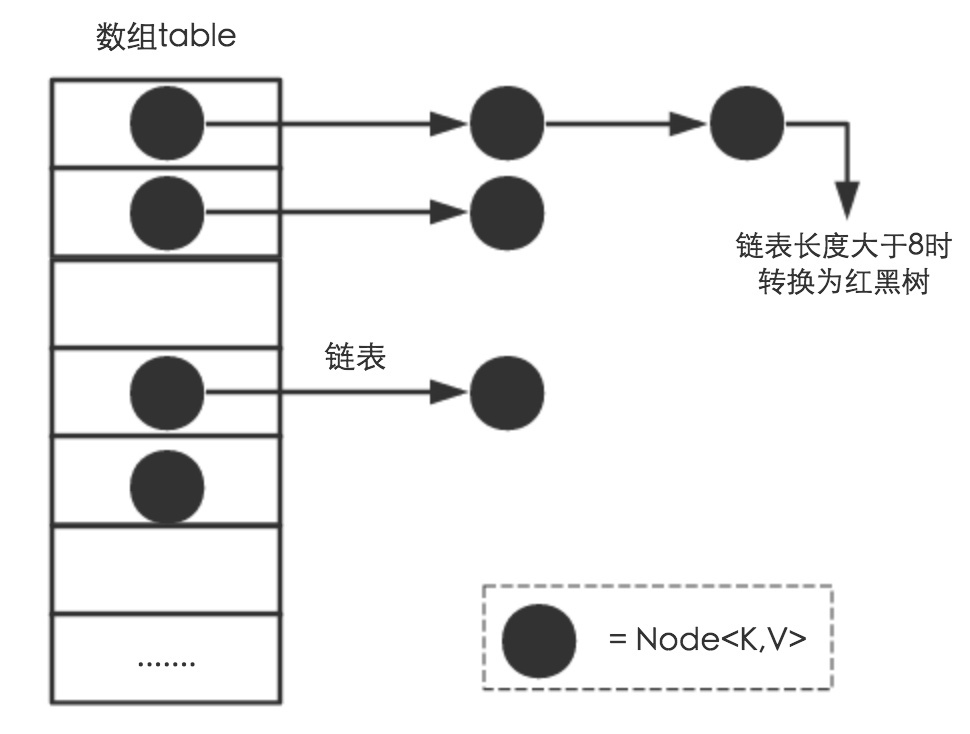
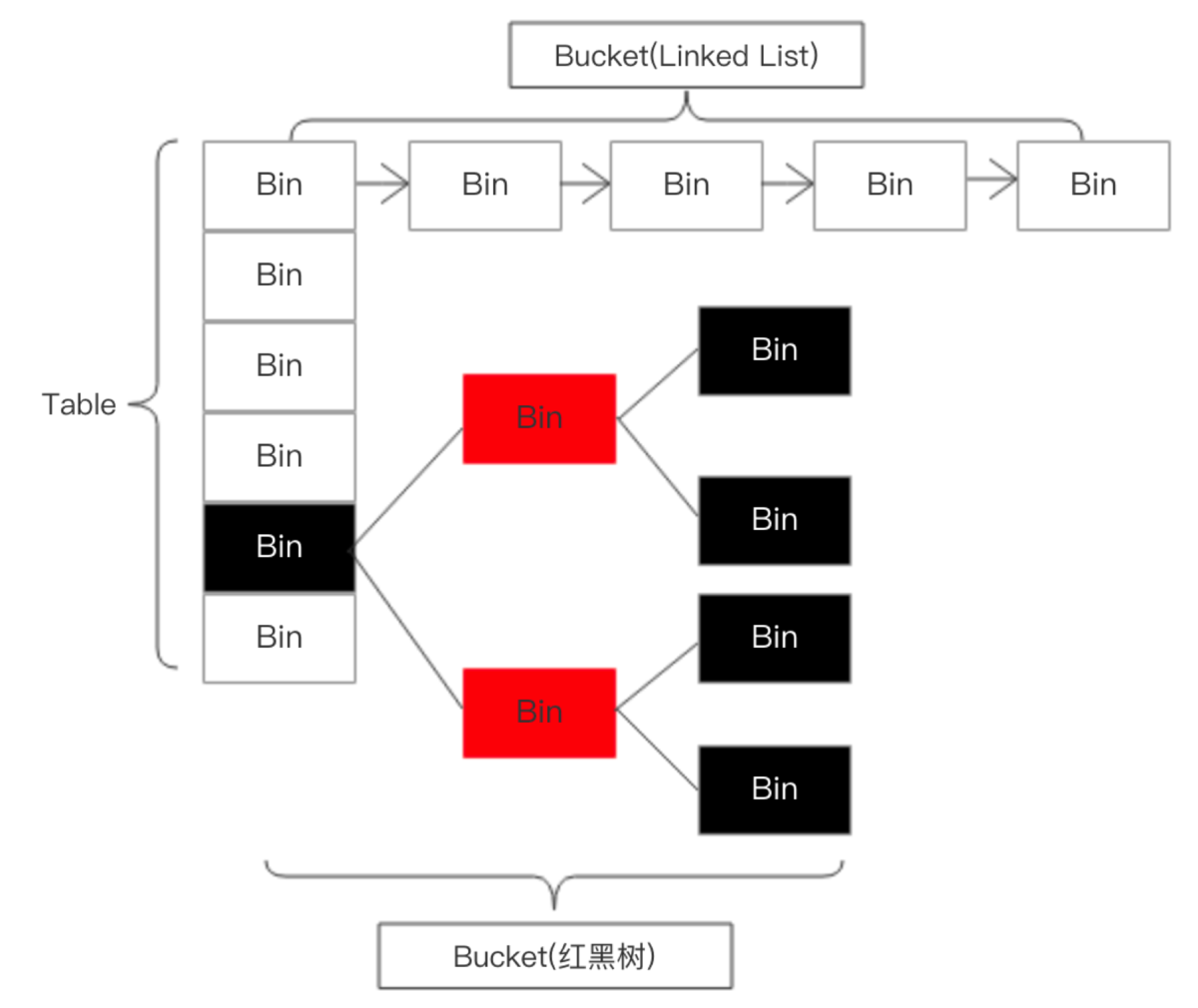
剖析put方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//hash函数就是扰动函数
//1. 尽可能减少哈希冲突
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//map数据结构图示中每个节点
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;//单向链表
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
transient Node<K,V>[] table;//默认值是null
//hash(key)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//第一次进来
Node<K,V>[] tab; Node<K,V> p; int n, i;
//第一次进来,第二次肯定不走
if ((tab = table) == null || (n = tab.length) == 0)
//第一次肯定会进来
//1. 对tab进行一个初始化操作
//2. 得到初始化数组的长度,赋值给了n
n = (tab = resize()).length;//n=16
//第一次肯定判断结果为null
if ((p = tab[i = (n - 1) & hash]) == null)
//tab[i] = 新的节点
tab[i] = newNode(hash, key, value, null);
else {
//哈希碰撞了,哈希冲突了.
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//key值冲突了.
//e = 数组中的旧的Node对象
e = p;
//hash虽然碰撞了,但是key是不一样
else if (p instanceof TreeNode)//判断是否为红黑树结构
//当链表的节点>8个,链表结构转成红黑树结构
//当红黑树节点<6个,恢复成链表结构
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//链表结构
for (int binCount = 0; ; ++binCount) {
//p代表的就是哈希碰撞位置的第一个Node对象
if ((e = p.next) == null) {//新的节点挂载到链表的末尾
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//新的节点可能和链表结构中的某个节点的key也是一样的
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
//e肯定是不为null
p = e;
}
}
if (e != null) { // existing mapping for key
//把旧的节点的value赋值给了oldValue,put方法的返回结果
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
//新值覆盖旧值
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
扩容方法
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
//第一进来就会执行到此处 , 16
//扩容因子是0.75
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
//初始化一个长度为16的数组
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
map集合的迭代方式
//第一种方式 - 将map集合中所有的key全部取出来放入到一个Set集合中.
//set集合 - 无序不可重复,map集合的key也是无序不可重复.
Set<Integer> sets = maps.keySet();
//遍历set集合
Iterator<Integer> iter = sets.iterator();
while(iter.hasNext()){
Integer key = iter.next();
String value = maps.get(key);
System.out.println(key+":"+value);
}
//第二种方式 - 将map集合中的每对key-value封装到了一个内置的Entry对象中
//然后将每个entry对象放入到Set集合中
Set<Map.Entry<Integer,String>> entries = maps.entrySet();
Iterator<Map.Entry<Integer,String>> iter2 = entries.iterator();
while(iter2.hasNext()){
Map.Entry<Integer,String> e = iter2.next();
Integer key = e.getKey();
String value = e.getValue();
System.out.println(key+"->"+value);
}
Map作业
int[] arr = {1,2,1,2,3,4,1,2,5,.....}
统计每个随机数出现的次数 - Map集合
String str = "sfhdsfkdfdfjdfjdfdjfdsa";
String[] arr = ["python","java","python","java","php","python"];
String str = "python java python java mysql java mysql php"; spilt("\\s")
1. 写一个程序统计每个品牌花费的总费用 - 统计类题型
2. 根据总费用降序排 - 可以暂时不做.
http://xzc.cn/sYtc8YkClM - 宝洁作业
http://xzc.cn/p5acBgPAHf - 基础弱的 - 1. 当天的代码2遍
2. 解决了哪些问题? 列一下自己尚未解决的问题?
排序
比较器接口Comparator
jdk8.0开始,在List接口中已经定义了排序的方法
void sort(Comparator<? super E> c)
分析:java.util.Comparator
[I]函数式接口 - 允许使用lambda表达式 package tech.aistar.day11; import tech.aistar.day10.Book; import java.util.ArrayList; import java.util.Comparator; import java.util.List; /** * 本类用来演示: 集合排序 * * @author: success * @date: 2021/7/30 9:29 上午 */ public class ListSortDemo { public static void main(String[] args) { Book b1 = new Book(1,"1001","java",100.0d); Book b2 = new Book(2,"1002","java",200.0d); Book b3 = new Book(3,"1003","java",200.0d); Book b4 = new Book(4,"1004","python",300.0d); List<Book> bookList = new ArrayList<>(); bookList.add(b1); bookList.add(b2); bookList.add(b3); bookList.add(b4); // bookList.sort(new Comparator<Book>() { // @Override // public int compare(Book o1, Book o2) { // if(o1.getPrice()>o2.getPrice()) // return -1; // else if(o1.getPrice()<o2.getPrice()) // return 1; // return 0; // } // }); //根据价格降序排 // bookList.sort((o1,o2)->{ // if(o1.getPrice()>o2.getPrice()) // return -1; // else if(o1.getPrice()<o2.getPrice()) // return 1; // return 0; // }); //根据编号降序排 - String类型 // bookList.sort((o1, o2) -> o2.getIsbn().compareTo(o1.getIsbn())); //根据价格降序排,如果价格一样的话,按照编号继续降序排 bookList.sort((o1,o2)->{ if(o1.getPrice()>o2.getPrice()) return -1; else if(o1.getPrice()<o2.getPrice()) return 1; return o2.getIsbn().compareTo(o1.getIsbn()); }); for (Book book : bookList) { System.out.println(book); } } }
可比较接口
排序的对象对应的实体类实现java.lang.Comparable
接口 package tech.aistar.day11.compares; /** * 本类用来演示: * * @author: success * @date: 2021/7/30 10:53 上午 */ public class Teacher implements Comparable<Teacher>{ private int id; private String name; private int age; public Teacher() { } public Teacher(int id, String name, int age) { this.id = id; this.name = name; this.age = age; } public int getId() { return id; } public void setId(int id) { this.id = id; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { final StringBuilder sb = new StringBuilder("Teacher{"); sb.append("id=").append(id); sb.append(", name='").append(name).append('\''); sb.append(", age=").append(age); sb.append('}'); return sb.toString(); } @Override public int compareTo(Teacher o) { //定制排序的规则 return o.age - this.age; } }package tech.aistar.day11.compares; import java.util.ArrayList; import java.util.Collections; import java.util.List; /** * 本类用来演示: * * @author: success * @date: 2021/7/30 10:54 上午 */ public class TestTeacherSort { public static void main(String[] args) { Teacher t1 = new Teacher(1,"tom",23); Teacher t2 = new Teacher(2,"jack",25); Teacher t3 = new Teacher(3,"james",18); Teacher t4 = new Teacher(4,"rose",17); List<Teacher> list = new ArrayList<>(); list.add(t1); list.add(t2); list.add(t3); list.add(t4); // for (Teacher teacher : list) { // System.out.println(teacher); // } Collections.sort(list); for (Teacher teacher : list) { System.out.println(teacher); } } }
Collections
java.util.Collections[C] - 集合工具类
面试题 - Collection和Collections有什么区别?
static
void sort(List list, Comparator<? super T> c)
根据指定的比较器引起的顺序对指定的列表进行排序。Collections.sort(bookList,((o1, o2) -> (int) (o2.getPrice()-o1.getPrice())));
- static <T extends Comparable<? super T>> void sort(List
list) ;//集合中的对象必须要实现java.lang.Comparable可比较接口
HashSet
Set[I]接口下的实现类 - 存储的数据是无序不可重复复的.
添加数据到容器的原理:
- 当把对象添加到容器中之前,会调用对象的hashCode方法,得到一个哈希值.
- 如果这个哈希值在这之前没有出现过,说明这个位置没有被占用,那么就可以直接将这个对象放入到这个容器中的这个位置
- 如果这个哈希值在这之前出现过了.产生了哈希碰撞或者哈希冲突.但是这个时候,还不能确定哈希碰撞的俩个对象是同一个对象
- 继续调用对象的equals方法,如果返回true,说明是同一个对象.则拒绝添加.
底层数据结构
- 散列表
- 桶数组 + 链表 + 红黑树
查看HashSet源码
Set
sets = new HashSet<>(); public HashSet() { //HashSet的底层是HashMap map = new HashMap<>(); }HashSet的add方法的底层
private static final Object PRESENT = new Object(); //此处的e是添加到容器中的对象 public boolean add(E e) { //实际上还是在调用map的put方法 //HashSet中添加的对象是作为了Map集合的key //Map的key具有什么特点 = HashSet中的数据有何特点. return map.put(e, PRESENT)==null; }
面试题
HashMap 和 HashTable 区别
HashMap 是 HashTable 的轻量级实现,他们都完成了Map 接口,主要区别在于 HashMap 允许 null key 和 null value,由于非线程安全,效率上可能高于 Hashtable。主要区别如下:
HashMap允许将 null 作为一个 entry 的 key 或者 value,而 Hashtable 不允许。
HashMap 把 Hashtable 的 contains 方法去掉了,改成 containsValue 和 containsKey。因为 contains 方法容易让人引起误解。
HashTable 继承自 Dictionary 类,而 HashMap 是 Java1.2 引进的 Map interface 的一个实现。
HashTable 的方法是 Synchronize 的,而 HashMap 不是,在多个线程访问 Hashtable 时,不需要自己为它的方法实现同步,而 HashMap 就必须为之提供外同步。
Hashtable 和 HashMap 采用的 hash/rehash 算法都大概一样,所以性能不会有很大的差异。
ArrayList和LinkedList区别
- ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
- 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
- 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
List和Set区别
两个接口都是继承自Collection,是常用来存放数据项的集合,主要区别如下:
- List和Set之间很重要的一个区别是是否允许重复元素的存在,在List中允许插入重复的元素,而在Set中不允许重复元素存在。
- 与元素先后存放顺序有关,List是有序集合,会保留元素插入时的顺序,Set是无序集合。
- List可以通过下标来访问,而Set不能。
HashSet和HashMap区别
HashSet的底层是HashMap
HashMap HashSet HashMap实现了Map接口 HashSet实现了Set接口 HashMap储存键值对 HashSet仅仅存储对象 使用put()方法将元素放入map中 使用add()方法将元素放入set中 HashMap中使用键对象来计算hashcode值 HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢
ArrayList和HashSet区别
1.HashSet 是不重复的 而且是无序的!
唯一性保证. 重复对象equals方法返回为true ,重复对象hashCode方法返回相同的整数
HashSet其实就是一个HashMap,只是你只能通过Set接口操作这个HashMap的key部分,
2.ArrayList是可重复的 有序的
特点:查询效率高,增删效率低 轻量级 线程不安全。
arraylist:在数据的插入和删除方面速度不佳,但是在随意提取方面较快
HashSet和TreeSet区别
一、HashSet
HashSet内部的数据结构是哈希表,是线程不安全的。
HashSet当中,保证集合中元素是唯一的方法。
通过对象的hashCode和equals方法来完成对象唯一性的判断。
假如,对象的hashCode值是一样的,那么就要用equals方法进行比较。
假如,结果是true,那么就要视作相同元素,不存。
假如,结果是false,那么就视为不同元素,存储。
注意了,假如,元素要存储到HashCode当中,那么就一定要覆盖hashCode方法以及equals方法。
二、TreeSet
TreeSet能够对Set集合当中的元素进行排序,是线程不安全的。
TreeSet当中,判断元素唯一性的方法是依据比较方法的返回结果是否为0,假如是0,那么是相同的元素,不存,假如不是0,那么就是不同的元素,存储。
TreeSet对元素进行排序的方式:
1、元素自身具备比较功能,也就是自然排序,需要实现Comparable接口,并覆盖其compareTo方法。
2、元素自身不具备比较功能,那么就要实现Comparator接口,并覆盖其compare方法。
除此之外,还要注意了,LinkedHashSet是一种有序的Set集合。
也就是其元素的存入和输出的顺序是相同的。
HashMap和TreeMap区别
HashMap的底层是Array,所以HashMap在添加,查找,删除等方法上面速度会非常快。而TreeMap的底层是一个Tree结构,所以速度会比较慢。
另外HashMap因为要保存一个Array,所以会造成空间的浪费,而TreeMap只保存要保持的节点,所以占用的空间比较小。
HashMap如果出现hash冲突的话,效率会变差,不过在java 8进行TreeNode转换之后,效率有很大的提升。
TreeMap在添加和删除节点的时候会进行重排序,会对性能有所影响。
ArrayList和Vector区别
- Vector是线程安全的,ArrayList不是线程安全的。
- ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍。
贪吃蛇
贪吃蛇算法 - LinkedList-操作头和尾-适合解决队列和栈列的业务题目
算法的思路
蛇移动,判断方向,#### - 坐标
- 蛇头节点的坐标getFirst() -> 移动之后的新的节点
- 不管新的节点是否为食物.蛇linkeList集合果断先将新的节点加入到该链表的头结点中.addFirst
- 判断新的节点如果是食物的节点,那么链表就不删除最后一个节点.否则删除链表的最后一个节点.
TreeSet[C]
简单了解一下
Set[I] - SortedSet[I] - TreeSet[C] - 底层是TreeMap[C] - 使map集合的key根据定制的规则来进行排序.
Set - 无序不可重复的.
TreeSet - 不可重复的,但是可以根据定制的排序规则来进行排序.
Stream
java.util.stream.Stream;
它和传统的集合框架在性能上的比较.



