集合框架
就是内存中的”容器对象” - 存储数据的.开发中来替代数组的使用.
结构
api:java.util
Collection[I]
- List[I] - 有序可重复
- ArrayList[C] - 线程不安全
- LinkedList[C]
- Vector[C] - 使用方式和ArrayList一样,但是线程安全的
- 方法都是采用synchronized
- Set[I] - 无序不可重复
- HashSet[C]
- SortedSet[I]
- TreeSet[C]
Map[I]
- HashMap[C] - key-value的形式存储数据的,针对key是无序不可重复.
- Hashtable[C]
- Properteis[C] - 属性文件在内存中的映射的对象
Collection[I]
- boolean add(E e);//向容器中添加一个元素
- void clear();//清空容器
- boolean contains(Object o);//判断容器中是否包含某个对象
- boolean isEmpty();//如果集合中没有数据,集合大小为0,返回true
- Iterator
iterator();// 获取集合对象的迭代器 - boolean remove(Object obj);//删除集合容器中第一次出现的这个对象.只能删除1个
- int size();//返回集合中的数据的个数 - 集合的大小
List[I]
特点 - 有序并且是可以重复的.
- E get(int index);//根据下标去取.集合下标边界[0,集合.size()-1]
- int indexOf(Object obj);//返回此列表中指定元素的第一次出现的索引,如果此列表不包含元素,则返回-1。
- E remove(int index);//根据下标删除,并且返回刚刚删除的那个元素
- Object[] toArray();//将集合转换成数组.
ArrayList[C]
特点:有序可重复的,底层数据结构就是一个”动态增长”的数组.
优点:因为数组是一个有序的序列,所以它可以通过下标直接取值 - 查询效率高.
缺点:增删效率会低.因为涉及到下标的移动.
分析源码
/**
* 默认的初始的容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
//就是真正的存储数据的数组
transient Object[] elementData;
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
//构造
public ArrayList() {
//1. 初始化elementData,长度为0
//2. 是为了后面的ensureCapacityInternal方法中判断是否是第一次调用add方法
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
//this.elementData = {}
}
剖析add方法
ArrayList扩容的原理
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }扩容方法
private void ensureCapacityInternal(int minCapacity) {//第一次进来1 if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {//true //第一次minCapacity = 10 minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity); } ensureExplicitCapacity(minCapacity); }继续ensureExplicitCapacity(minCapacity);
private void ensureExplicitCapacity(int minCapacity) { modCount++; // overflow-conscious code //第一次进来10-0>0 if (minCapacity - elementData.length > 0) grow(minCapacity); }
grow(minCapacity)private void grow(int minCapacity) { // 第一次 //oldCapacity = 0 //newCapacity = 0 int oldCapacity = elementData.length; int newCapacity = oldCapacity + (oldCapacity >> 1);//1.5倍 if (newCapacity - minCapacity < 0)//第一次会进来 newCapacity = minCapacity;//newCapacity = 10 if (newCapacity - MAX_ARRAY_SIZE > 0) newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win: //第一次执行add方法的时候,底层会给我们初始化了一个长度为10的Object[]数组 elementData = Arrays.copyOf(elementData, newCapacity); }
集合的遍历
直接输出
增强for循环 - 只读
只读的循环.如果在循环的过程中进行了remove操作 - 抛出java.util.ConcurrentModificationException并发修改异常 实际的底层,调用迭代器对象中的next方法 private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount; public E next() { checkForComodification(); //.... } final void checkForComodification() { //modCount是当初调用add方法,添加1个元素,modCount自增1个 if (modCount != expectedModCount) throw new ConcurrentModificationException(); } } 发现只要调用了remove方法 - modCount++ private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // clear to let GC do its work }
普通for
迭代器
因为不同的集合的底层的数据结构是不一样的.数据结构不一样,它的遍历方式不一样
为了访问/遍历不同数据结构的集合提供一种统一的遍历方式
//1. 获取集合的迭代器 Iterator<Long> iter = list.iterator(); //2. 调用hasNext方法 while(iter.hasNext()){//判断迭代器中是否仍有下一个元素可被迭代 Long p = iter.next();//获取当前迭代的 System.out.println(p); }
jdk8提供的新的遍历方式
list.forEach(new Consumer<Long>() {//匿名内部类 @Override public void accept(Long aLong) { System.out.println(aLong); } }); //lambda表达式来替代匿名内部类的写法 //配合函数式接口[只能包含一个抽象方法] System.out.println("======lambda===="); list.forEach(e -> System.out.println(e)); System.out.println("========"); list.forEach(System.out::println);
LinkedList[C]
有序的序列,底层的数据结构双向链表,jdk6以及之前是双向循环链表
链表结构的特点:查询效率很低,每次都会从头节点开始遍历.但是增删效率高,只会涉及到相邻节点的移动.
适合解决栈列和队列的业务题型 - 贪吃蛇
栈列 - 先进后出
队列 - 先进先出
链表结构
相对于数组这种数据结构,需要占用更多的内存.每个节点除了保存具体的数据,还需要保存相邻节点的地址.
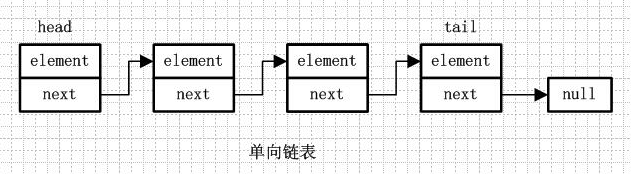
单向链表
head - 头节点
tail - 尾节点
element - 节点中真正的保存的数据
next - 下一个节点的地址
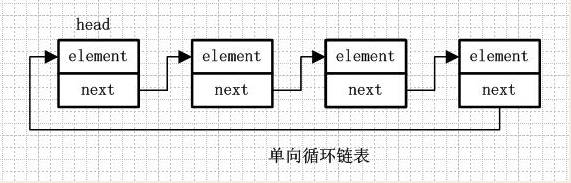
单向循环链表
尾节点的next又指向了头节点.
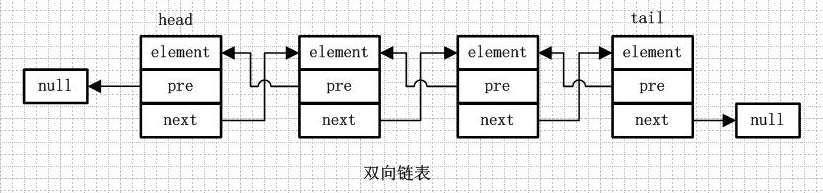
双向链表 - LinkedList底层数据结构
增加了一个pre - 保存的是上一个节点的地址.
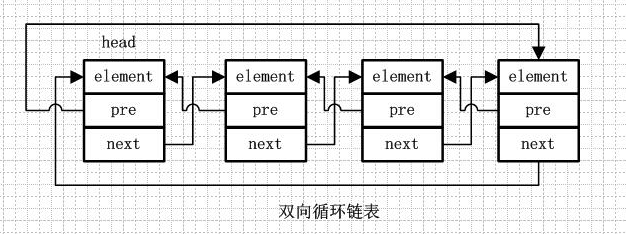
双向循环链表
剖析源码
//Node代表的是链表的节点
private static class Node<E> {
E item;//真正的元素
Node<E> next;//下一个节点的地址
Node<E> prev;//上一个节点的地址
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
//双向链表如何插入一个新的节点
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
//第一次进入last最后一个节点Node - null
final Node<E> l = last;//l = null
//第二次进入 l = new Node<>(null,"ok",null)
//第一次进入
//newNode = new Node<>(null,"ok",null)
//第二次进入
//newNode = new Node<>(链表中原来的最后一个节点l, "java", null);
final Node<E> newNode = new Node<>(l, e, null);
//新插入的节点肯定是作为最后一个节点 - 尾节点
last = newNode;
if (l == null)//第一次进入,链表之前没有任何元素
first = newNode;//新的节点作为头节点
else
//原来链表中的最后一个节点的next同时也指向新的节点
l.next = newNode;
size++;
modCount++;
}
查找源码
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
Node<E> node(int index) {//index = 3
// 假设集合中有10个元素 = size = 10
//index<5 - 链表的坐标
if (index < (size >> 1)) {
Node<E> x = first;//确定头节点
for (int i = 0; i < index; i++)
x = x.next;
//① - x第二个 ,i=0
//i=1 x第三个
//i=2 x第四个
return x;
} else {//index>=5
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
删除源码
public E remove(int index) {
checkElementIndex(index);
//找到index对应的Node对象,传入到了unlink方法中.
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {//防止删除的是头节点
first = next;//需要删除的那个节点的下一个节点作为头节点了.
} else {//删除的是中间节点
prev.next = next;//原来节点的上一个节点的next指向原来节点的下一个节点
x.prev = null;//优化,更快让GC会回收pre指针.
}
if (next == null) {//删除的是尾结点
last = prev;//原来节点的上一个节点作为尾节点
} else {//删除的是中间节点
next.prev = prev;//原来节点的下一个节点指向原来节点的上一个节点
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
练习-括号匹配

package tech.aistar.day11.homework;
import java.util.LinkedList;
import java.util.Scanner;
/**
* 本类用来演示: 括号匹配
*
* @author: success
* @date: 2021/7/29 1:51 下午
*/
public class BracketsDemo {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
System.out.print("输入括号:>");
String line = sc.nextLine();
if(matches(line)){
System.out.println("匹配");
}else{
System.out.println("不匹配");
}
}
private static boolean matches(String line) {
//1. 将字符串转成字符数组
char[] arr = line.toCharArray();
//2. 新建一个LinkedList集合
LinkedList<Character> list = new LinkedList<>();
//3. 将数组中的第一个元素压入栈顶
list.push(arr[0]);
//4. 从arr数组的第二个位置开始遍历
for (int i = 1; i < arr.length; i++) {
//()[]{}
//获取当前的arr[i]
Character c = arr[i];
//为了避免在栈顶已经没有元素的情况下还去获取栈顶元素,非空判断
if(list.isEmpty()){
list.push(c);
continue;
}
//5. 先获取栈顶元素
Character top = list.getFirst();
//6. 栈顶元素和当前的arr[i]进行匹配
if(top.equals('(')&&c.equals(')') || top.equals('{')&&c.equals('}') || top.equals('[')&&c.equals(']')){
//弹出栈顶元素
list.pop();
}else{
//继续将当前的arr[i]压入栈顶
list.push(c);
}
}
return list.isEmpty();
}
}



